
Just when you thought Generative AI couldn't get any more realistic, Google goes and drops a bombshell: VLOGGER, an AI model that can generate high-fidelity video avatars from a single photograph. We're talking uncannily lifelike facial expressions, body movements, and even subtle gestures like blinking – all synthesized from a static image. Talk about taking the "talking head" concept to a whole new level!
The Era of Embodied Avatar Synthesis
The demand for realistic and engaging virtual avatars has never been higher. From video games and virtual reality experiences to online communication and entertainment, embodied avatars have become an integral part of our digital lives. Enter VLOGGER, a groundbreaking multimodal diffusion model that is set to revolutionize the field of embodied avatar synthesis.
What is VLOGGER?
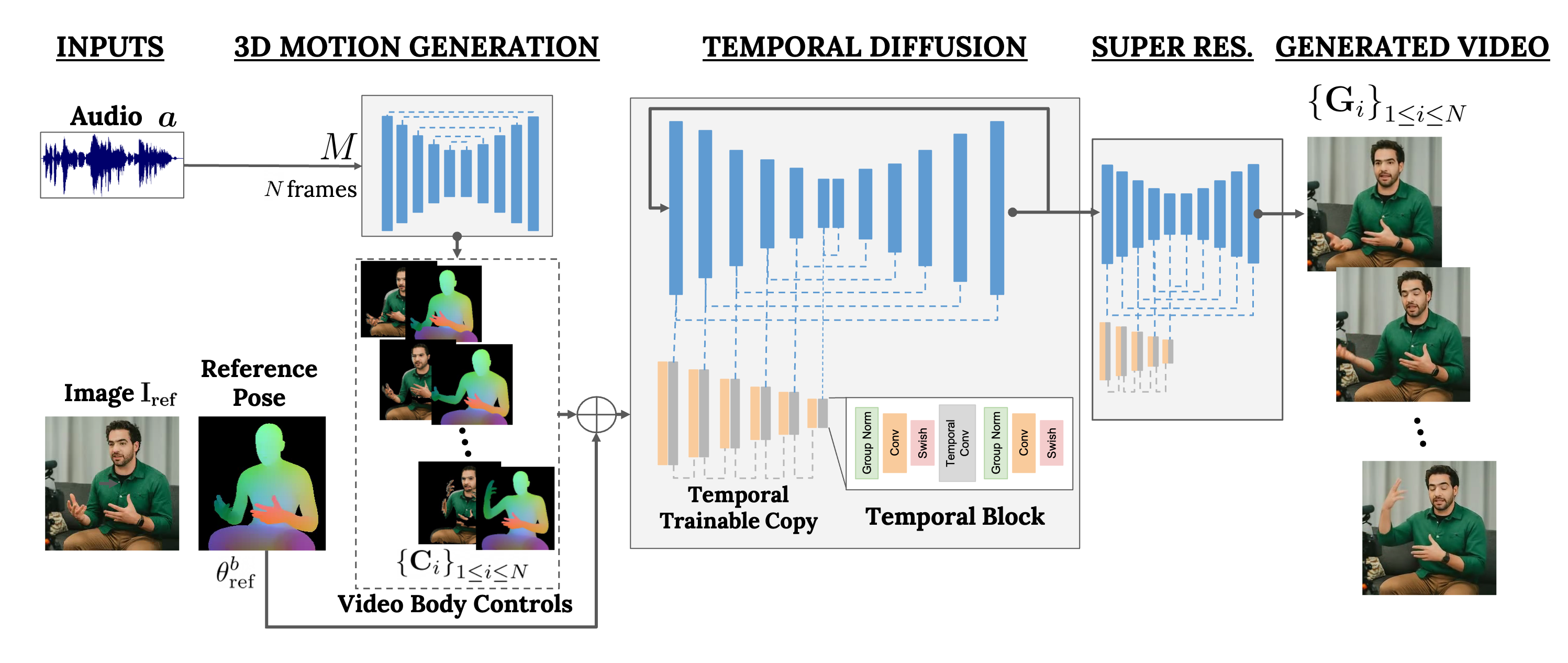
VLOGGER, or "Multimodal Diffusion for Embodied Avatar Synthesis," is a novel method for generating text and audio-driven talking human videos from a single input image. Building on the success of recent generative diffusion models, VLOGGER enables the creation of high-quality, variable-length videos that are easily controllable through high-level representations of human faces and bodies.
Behind the Scenes - The Cutting-Edge Tech Powering VLOGGER
Of course, the team at Google didn't just stumble upon this mind-bending capability by accident. VLOGGER is a masterclass in cutting-edge deep learning techniques, combining multimodal AI models, large language models, and diffusion-based image synthesis to achieve its uncanny realism.
From using transformers to predict realistic body movements based on audio cues to fine-tuning the model on massive datasets of human speech and gestures, the technical wizardry behind VLOGGER is nothing short of awe-inspiring. But as with any powerful technology, the real challenge lies in ensuring its responsible development and deployment.
Two-Stage Pipeline - Stochastic Human-to-3D-Motion Diffusion and Temporal Image-to-Image Translation
At the heart of VLOGGER is a two-stage pipeline that leverages stochastic diffusion models to map speech to video. The first network takes an audio waveform as input and generates intermediate body motion controls, which govern gaze, facial expressions, and pose throughout the video. The second network, a temporal image-to-image translation model, uses these body controls and a reference image of the target person to generate the corresponding video frames.
Advantages of VLOGGER over Previous Methods
VLOGGER sets itself apart from previous methods in several key ways. First, it doesn't require training for each individual person, making it more versatile and efficient. Second, it doesn't rely on face detection and cropping, instead generating the complete image. Finally, VLOGGER considers a wide range of scenarios, including visible torsos and diverse subject identities, which are crucial for accurately synthesizing communicating humans.
Evaluating VLOGGER's Performance on Benchmarks
To assess its performance, VLOGGER was evaluated on three different benchmarks. The results were impressive, with the proposed model surpassing other state-of-the-art methods in image quality, identity preservation, and temporal consistency. This rigorous testing demonstrates VLOGGER's superiority in the field of embodied avatar synthesis.
Image Quality
On the first benchmark, VLOGGER demonstrated superior image quality when compared to existing methods. This is a crucial aspect of embodied avatar synthesis, as the generated videos must be visually indistinguishable from reality to be truly immersive and engaging.
The implications of VLOGGER's high image quality are far-reaching. In the entertainment industry, for instance, it could enable the creation of hyper-realistic virtual actors and characters, opening up new realms of storytelling and creative expression. Additionally, in fields such as virtual communication and online education, high-quality avatars could enhance the sense of presence and connection, making remote interactions feel more natural and engaging.
Identity Preservation
Another area where VLOGGER excelled was identity preservation. This means that the generated videos accurately maintained the identity and likeness of the subject, even as their expressions and movements changed throughout the video.
Identity preservation is essential for applications that require consistency and continuity, such as virtual assistants or digital influencers. By ensuring that the avatar's appearance remains faithful to the original subject, VLOGGER could help build trust and familiarity with users, enhancing the overall experience.
Temporal Consistency
Finally, VLOGGER outperformed other methods in temporal consistency, which refers to the smooth and natural transitions between frames in the generated video. This aspect is crucial for creating believable and lifelike avatars that move and communicate in a realistic manner.
Temporal consistency has implications in various fields, such as gaming and virtual reality, where seamless and immersive experiences are paramount. With VLOGGER's ability to generate videos with consistent motion and expression changes, developers could create more engaging and compelling virtual environments and characters.
The MENTOR Dataset, A New Standard for Avatar Synthesis
To train and ablate their main technical contributions, the researchers behind VLOGGER collected a new and diverse dataset called MENTOR. This dataset is an order of magnitude larger than previous ones, containing 2,200 hours and 800,000 identities, with a test set of 120 hours and 4,000 identities. The scale and diversity of MENTOR make it a valuable resource for future research in the field.
The Possibilities: From Helpful Assistants to Full-Blown Avatars
Now, the researchers behind VLOGGER are painting a rosy picture of how this tech could lead to more relatable and empathetic helpdesk agents, personalized virtual assistants, and enhanced online communication and education experiences. And sure, the idea of having a friendly, human-like avatar guiding you through that mind-numbing software tutorial does sound appealing. But let's be real – we all know where this is headed.
Generating Diverse and Realistic Videos with VLOGGER
One of the standout features of VLOGGER is its ability to generate a diverse distribution of realistic videos from a single subject image. The model captures significant head and body movements while keeping the background fixed, resulting in a wide range of realistic videos that showcase the subject's dynamic presence.
Video Editing Applications: Changing Expressions and More
VLOGGER's flexibility as a diffusion model opens up exciting possibilities for video editing. By inpainting specific image parts, such as the mouth or eyes, VLOGGER can change a subject's expression while maintaining consistency with the original, unchanged pixels. This feature has the potential to revolutionize post-production video editing and enhance the creative process.
Generating Moving and Talking People from a Single Image
Perhaps one of the most impressive applications of VLOGGER is its ability to generate moving and talking people from just a single input image and a driving audio. The examples provided showcase the model's remarkable capacity to bring static images to life, creating dynamic, engaging videos that capture the essence of the subject.
Video Translation: Bridging the Language Gap
VLOGGER also excels in video translation, taking an existing video in one language and seamlessly editing the lip and face areas to match a new audio track in another language. This feature has the potential to break down language barriers and make video content more accessible to a global audience.
The Catch: Deepfakes and the Erosion of Digital Trust
With great power comes great potential for misuse, and VLOGGER is no exception. Imagine the chaos that could ensue if malicious actors got their hands on this tech and started churning out deepfake videos of public figures saying or doing things they never did. We're talking political scandals, financial market manipulation, or even inciting violence – all powered by eerily convincing synthetic media.
And that's not even the worst part. As these deepfakes become increasingly indistinguishable from reality, how can we maintain trust in any digital content? Every video, every image, every sound bite could potentially be fabricated, leaving us adrift in a sea of misinformation and uncertainty.
The Future of Embodied Avatar Synthesis: Potential Applications and Implications
As VLOGGER demonstrates, the future of embodied avatar synthesis is bright. With its ability to generate diverse, realistic videos from minimal input, VLOGGER has the potential to transform various industries, from entertainment and gaming to education and virtual communication. As research in this field continues to advance, we can expect to see even more impressive and versatile tools for bringing avatars to life, blurring the lines between the virtual and the real.
Ethical Considerations and Potential Solutions
As VLOGGER and similar technologies continue to advance, we find ourselves at a crossroads. Do we embrace these innovations wholeheartedly, accepting the risks in pursuit of their potential benefits? Or do we slam on the brakes, erring on the side of caution to prevent the erosion of trust in digital media?
The truth, as always, lies somewhere in the middle. We need robust ethical frameworks, transparent development processes, and proactive measures to combat the spread of deepfakes. This could involve exploring authentication methods, digital watermarking, and fostering media literacy to help the public discern fact from fiction.
Ultimately, the onus is on researchers, policymakers, and tech companies to navigate this minefield responsibly. Because as cool as having a digital avatar might be, preserving the integrity of our shared reality is infinitely more important.
So let's enjoy the technological marvels of VLOGGER and its ilk, but let's also stay vigilant. The uncanny valley has never looked so alluring – or so treacherous.

Comments