

As large language models (LLMs) like GPT-4 become more powerful and prevalent, determining which one to use for a given task is crucial yet challenging.
Despite the plethora of scientific benchmarks for evaluating Language Learning Models (LLMs), these metrics often fall short in assessing an LLM's capability to handle diverse, real-world business tasks.
Here's a practical framework to evaluate LLMs based on five key factors: fundamental abilities, knowledge base, creativity, cognition and censorship.
The Quandary in LLM Assessment
Every week brings new benchmarks and 'scientific' tests evaluating the performance of LLMs like GPT-4. However, these metrics seldom provide clear guidance on how an LLM will fare in the complexities of a real-world business setting. Given the nuanced demands and various stakeholders involved, companies find themselves in a quandary. It becomes crucial to look beyond these benchmarks to discern an LLM's efficacy for particular tasks.
The Limits of Measures like Perplexity in Benchmarking LLMs
When evaluating LLMs, many rely on metrics like perplexity to benchmark model performance. However, perplexity has significant limitations in predicting real-world efficacy:
- Perplexity is an abstract mathematical measure of how "surprised" a model is by test data. This does not directly translate to output quality.
- Numerical benchmarks ignore nuanced human factors like tone, personality, and contextual relevance.
- Perplexity is insensitive to creativity, emotional resonance, and other subjective markers of quality writing.
- A single score cannot capture suitability across diverse use cases and applications.
- For end users, perplexity offers little practical insight on an LLM's capabilities.
- Workflows using multiple specialized LLMs require custom scoring to match models to specific tasks. Broad benchmarks provide limited guidance.

- BLEU compares machine outputs to reference translations quantitatively. But high scores sometimes poorly correlate with human quality judgments.
- ROUGE measures summary quality through overlap with reference summaries. However, high scores may just indicate repetition rather than high quality.
- Diversity metrics evaluate the uniqueness of model outputs. But diversity alone doesn't guarantee coherence or usefulness.
- The standard human evaluation criteria of relevance, fluency, coherence and overall quality have become antiquated and unrevealing. Testing those basic language competencies simply verifies expected fundamentals, providing little useful insight. It's akin to assessing a management candidate's reading comprehension - necessary but hardly sufficient for gauging suitability.
All current techniques have significant limitations. Automated metrics may reward the exploitation of flaws rather than true capability. While mathematical rigor appeals to developers, raw perplexity has minimal bearing on practical performance.
Nuanced real-world testing combined with bespoke scoring frameworks offer better insight on an LLM's capabilities. Beware overreliance on general benchmarks. Evaluate models on the exact skills your use cases demand rather than theoretical universal metrics.
The Overlooked Need for Practical LLM Benchmarking
The rapid advancement of large language models is outpacing evaluation capabilities, at a time when benchmarking grows more vital:
- With exponential use case growth, no single LLM suits every domain and need.
- Workflows integrating multiple specialized LLMs require rigorous matching to subtasks.
- Blending LLMs into Generative AI Networks and workflows demands precision benchmarking to optimize configurations.
- Novel applications like autonomous agents need to be tailored LLM testing to predict performance.
- Intricate prompt engineering depends on benchmarks to select optimal models.
- LLM proliferation means more candidate models to evaluate for any given task.
Additionally, benchmarking techniques have stagnated despite recent radical LLM advances:
- Evaluation methods like perplexity have remained largely static for years.
- But LLM capabilities are now expanding exponentially thanks to transformers and massive datasets.
- Fixed benchmarks fail to capture dramatic qualitative improvements in recent models.
- Old methodologies focused on a narrow set of tasks rather than adaptable general intelligence.
- They emphasize rigid numerical metrics over real-world performance and output quality.
Benchmarking strategies are outdated given recent leaps in large language model abilities. Custom testing is now essential to tap their potential responsibly. With AI infiltrating society, we require evaluations that illuminate each model's specialized skills. As supermarket metrics fail, progress demands bespoke precision to guide these technologies' immense possibilities.
Understanding How LLMs Actually Work
When assessing LLMs, it's important to recognize how they differ from human intelligence.
LLMs like GPT-4 don't comprehend meaning profoundly. They identify sequences of words that tend to appear together frequently based on their training data. This allows them to predict adjacent words and generate coherent text but does not imply deep reasoning.
Modern LLMs use complex algorithms that can produce remarkably creative or insightful-seeming results. However, these models have no underlying consciousness, emotions, or subjective experience. Any appearance of genuine creativity is an illusion stemming from their statistical foundations.
While LLMs keep advancing, prompt engineers must remember what's happening under the hood. Their outputs do not constitute true human-level comprehension or imagination. Proper oversight means leveraging LLMs' statistical superpowers while understanding their limitations compared to the depth of the human mind.
Accounting for how LLMs differ fundamentally from biological cognition is key to setting realistic expectations. Their prodigious yet superficial talents can augment human capabilities, but should not be mistaken as equivalent (at this moment). Understanding the statistical patterns driving their outputs allows for properly aligning them to use cases without overestimating their abilities.
1. Fundamental LLM Abilities
The most foundational capabilities to evaluate in an LLM are its fundamental skills for manipulating and generating text. These include:
- Comprehension: How accurately can the LLM extract semantics and sentiment from text? Assess its skills at tasks like classification, summarization, and translating intent.
- Text Manipulation: Evaluate abilities like grammar error correction and word substitution. These are key for tasks like text refinement and augmentation.
- Analysis: Rate how well the LLM can parse text to extract entities, determine sentiment, assess complexity, etc. These support use cases like search and recommendation engines.
- Generation: Test the coherence, relevance, and overall quality of the LLM's text generation for different prompts and contexts. Assess creative output as well.
Thoroughly testing these core competencies on sample inputs from your use cases is crucial. They provide the building blocks for more advanced applications. An LLM may boast strong creative abilities, but falter at basics like sentiment analysis or grammar correction needed for your needs. Match fundamental talents to use case requirements.
 Sunil Ramlochan - Enterprise AI Specialist
Sunil Ramlochan - Enterprise AI Specialist
2. LLM Knowledge: Breadth Vs. Depth
LLMs are only as good as their training data. Most have broad knowledge from ingesting millions of texts but lack expertise in niche domains. Consider both the breadth and depth of an LLM's knowledge base. If industry- or topic-specific information is crucial, opt for an LLM trained on that specialized data or allow further training. For general knowledge needs, larger models like GPT-4 have wider coverage.
What LLMs 'Know'
LLMs like GPT-4 can store immense amounts of data, but their cognition is not akin to human understanding. They can generate accurate or flawed data, and their knowledge has a 'cutoff' date, beyond which they cannot update themselves. Hence, their outputs need to be verified.
Breadth of Knowledge
LLMs are trained on diverse data sets, making them adept at generating text across multiple fields. This is useful for tasks requiring interdisciplinary insights.
Depth of Knowledge
While LLMs may lack genuine expertise, they can produce highly specialized text that appears expert-level. It's advisable not to mistake this for genuine depth of knowledge.
3. Creative Abilities of LLMs
When assessing an LLM's creativity, remember they lack true human creative facilities like intention, feeling, and original conception. Their outputs merely mimic certain markers of creativity based on patterns in their training data. With that caveat, useful categories for evaluation include:
- Insight Imitation: Test how convincingly the LLM can produce responses that give the illusion of intuition or meaningful observation.
- Emotional Resonance: Assess the model's ability to generate text with emotional affect, humour, or expressiveness that creates a subjective impression.
- Novelty: Rate the uniqueness, non-sequitur, and unpredictability of the LLM's outputs based on uncommon or random associations within its training data.
- Range and Versatility: Evaluate the diversity of topics, styles, and genres the LLM can replicate based on the breadth of its training corpora.
- Imagination: Examine outputs for the impression of playfulness, whimsy, and unbridled imagination, within the confines of its statistical foundations.
- Conceptual Generation: Test how plausibly the LLM can produce aspirational, goal-driven text without any true conception of goals.
Scoring an LLM's simulated creativity in these areas provides insight on use cases like creative writing, marketing content generation, or brainstorming support. Just remain cognizant that true human creativity remains beyond their reach.
4. Cognitive Capabilities of LLMs
While LLMs exhibit some human-like cognitive abilities, their skills are fundamentally different from biological cognition. However, certain cognitive factors are still useful to assess:
- Logical Reasoning: Assess the coherency, validity, and soundness of the LLM's reasoning given certain premises or constraints. Quantify error rates.
- Language Use: Gauge technical writing abilities including grammar, structure, and appropriate tone. Require high linguistic precision for use cases like legal tech.
- Sequential Tasks: Measure proficiency at tasks involving ordered steps like calculations, sorting datasets, or following chained instructions.
- Pattern Recognition: Benchmark capabilities to identify patterns in text, data, images and other multimedia. Critical for data analysis.
- Common Sense: While limited, gauge any glimmer of contextual common sense in the LLM's outputs when lacking a specific background.
Rating cognitive factors help match LLMs to analytical use cases requiring logic, reasoning, and technical language generation. But ultimately, their cognition remains statistical rather than experiential. Setting expectations accordingly allows for selectively targeting their strengths.
Distinguishing Cognition and Creativity in LLMs
When assessing LLMs, it's essential to analyze both their cognitive and creative capabilities separately:
Cognition for Structured Thinking
Cognitive skills allow an LLM to perform analytical tasks requiring:
- Logical reasoning
- Pattern recognition
- Data analysis
- Mathematical calculations
- Clear technical writing
These capacities suit use cases like financial analysis, legal review, and engineering specifications.
Creativity for Open-Ended Tasks
Alternatively, creative abilities provide advantages on unstructured tasks like:
- Brainstorming novel ideas
- Producing original stories
- Marketing content
- Conversational dialogue
- Whimsical ideation
Creativity reflects an open-ended, nonlinear thinking style distinct from rigorous cognition.
Carefully evaluate each LLM on both dimensions. The ideal model combines creative flare with analytical precision. But most will skew stronger on one axis. Match cognitive versus creative specialities to your use case needs. Don't assume one LLM suits every task - play to their differentiated strengths.
5. LLM Censorship
Increasingly aggressive censorship and content filtering aimed at making LLMs "safer" risks significantly degrading their capabilities:
- Overzealous censorship training corrodes an LLM's ability to address sensitive topics in reasonable ways.
- Blocking "dangerous" keywords prevents discussing them rationally in context. This fosters ignorance rather than understanding.
- Heavily filtered models struggle with nuance - they avoid anything potentially controversial rather than engaging it thoughtfully.
- Sandboxing LLMs into narrow, sterile responses hampers creativity and insight. Constraints should be carefully weighed.
- Excessive ethics filtering trains models to overcompensate, generating bland, repetitive responses to avoid perceived risk.
- Debiasing should focus on addressing real harms rather than enforcing conformity. Diverse opinions shouldn't be "debiased" away.
Sunil Ramlochan - Enterprise AI Specialist
While heavy LLM censorship risks impairing capabilities, some judicious benchmarking of content filtering can help:
- Identifying restricted topics reveals blindspots for responsible use.
- Comparing models' censorship enables tradeoff evaluation.
- Tracking changes provides insight on tightening restrictions over time.
- Documenting censorship by category assists appropriate model selection.
Censorship may affect publications or organizations like news media that need to address sensitive societal issues, excessive LLM censorship poses challenges:
- LLMs filtered to avoid controversy struggle to analyze complex topics like abortion or migration thoughtfully.
- Heavily restricted models fail when asked to reason about conflict objectively.
- Sandboxing LLMs to avoid "dangerous" content makes generating hard-hitting opinions difficult.
- Overzealous ethics filtering results in stale, repetitive perspectives on charged issues.
- Censoring terms limits discussing them meaningfully even in appropriate contexts.
As interest grows in nuanced opinions beyond politically correct orthodoxies, censorship becomes more limiting. As such having censorship on your scorecard provides valuable insights on an LLM's limitations and guides responsible prompt engineering.
6. What Are Hallucinations and Why Do They Matter in LLMs?
Hallucinations in the context of large language models (LLMs) refer to the tendency for these AI systems to generate fictional facts, statements, and content that have no basis in reality. When an LLM "hallucinates," it is essentially imagining or fabricating information that is untrue or unverified.
This matters greatly because the purpose of LLMs is typically to provide useful information to human users. If an LLM begins hallucinating falsehoods, it can quickly become unreliable and misleading. Some examples of problematic hallucinations:
- In a customer service chatbot, providing made-up details about a product that don't reflect the real item.
- In a medical advice application, imagining symptoms or conditions the patient doesn't actually have.
- In a legal research tool, fabricating case law details and fictional judicial opinions.
- In an educational app, generating subjective opinions or biased perspectives not grounded in facts.
LLMs are prone to hallucinating when they lack sufficient training data for a particular query, when prompt engineering fails, or when the models overextend themselves beyond their actual knowledge. Unchecked, their tendency to "fake it" leads users astray.
Measuring and minimizing hallucination is thus critical to developing safe, trustworthy LLMs. Vectara's leaderboard provides visibility into different models' hallucination rates. Over time, techniques like improved dataset curation, tighter prompt formulation, and better uncertainty modelling will hopefully reduce hallucinatory errors. But for now, hallucinations remain an active area of LLM risk requiring vigilance.
The Ideal: LLMs Admitting Knowledge Gaps Rather Than Hallucinating Convincingly
When evaluating different LLMs, one ideal trait is the ability to admit knowledge gaps and ask for clarification rather than hallucinating detailed but false information.
The major risk with LLM hallucinations is how persuasive they can be. Because large language models are trained on massive datasets, they are adept at generating responses that seem highly plausible, even when fabricated.
This plausibility makes it easy even for humans to be misled by LLM falsehoods. Made-up "facts" contain rich detail and appeal to intuition. But they dangerously pass as truth without external verification.
So during LLM selection, it is preferable to choose models that avoid hallucination risks by proactively indicating when they lack sufficient information to answer a question. The ideal response is "I do not have enough context to respond accurately" rather than imaginative speculation.
Explicitly acknowledging the limits of their knowledge makes an LLM's hallucination tendency transparent. While not as satisfying for the user, this approach promotes truthful dialogue. Developing the discernment to identify their own knowledge gaps is an important evolution for more trustworthy LLMs.
Other LLM Factors to Consider
After assessing an LLM's core competencies, knowledge, and abilities, other practical factors also influence selection:
- Speed: The latency between providing a prompt and receiving output varies across models. Opt for an LLM fast enough to deliver results within the required timeframes.
- Context: The amount of prompt an LLM can ingest affects performance. Models with longer context windows better interpret prompts with more background info.
- Cost: LLMs differ in pricing models - peruse, subscriptions, etc. Calculate costs based on expected request volumes.
- Open vs Closed Source: Open source offers more transparency but can lack user support. Closed source provides dependable service but less visibility.
- Interface: Ease of integrating an LLM's API impacts developer experience. Assess the complexity of implementation.
- Token Limits: Lengthier outputs require more tokens which affect costs and capabilities. Match token limits to expected needs.
While not dealbreakers, these secondary factors allow for fine-tuning of the selection process. Combined with assessing core competencies and requirements, prompt engineers can make judicious LLM choices tailored to use case goals, budgets, and technical needs. The boom in generative AI means scrutiny is required to cut through the hype and find the best fit.
Build Customized Scorecards to Match LLMs to Use Cases
When adopting LLMs in an organizational setting, prompt engineers should develop customized scorecards to evaluate models for their particular needs. Don't rely solely on vendor-provided or third-party benchmarks. Create a framework of requirements specific to your business objectives, workflows, and applications.
This process involves rigorously testing leading LLMs on actual tasks and content from your operations. Develop a methodology to score their performance across factors like accuracy, tone, creativity, and more. Continually update these assessments as new models emerge and your needs evolve.
Additionally, catalogue detailed requirements for each project or workflow where you intend to deploy LLMs. This allows matching the appropriate model to individual use cases based on their specialized scorecard ratings. A marketing content generation task may demand high creativity, while a customer service application favours strong analytical cognition. Consult your scorecards to select the optimal LLM for the job.
By taking the time to develop customized benchmarks and requirements aligned with your business objectives, prompt engineers can make informed decisions on implementing LLMs. The technology continues advancing rapidly - dedicated scorecards help determine which models excel at your unique needs amidst the swell of options.
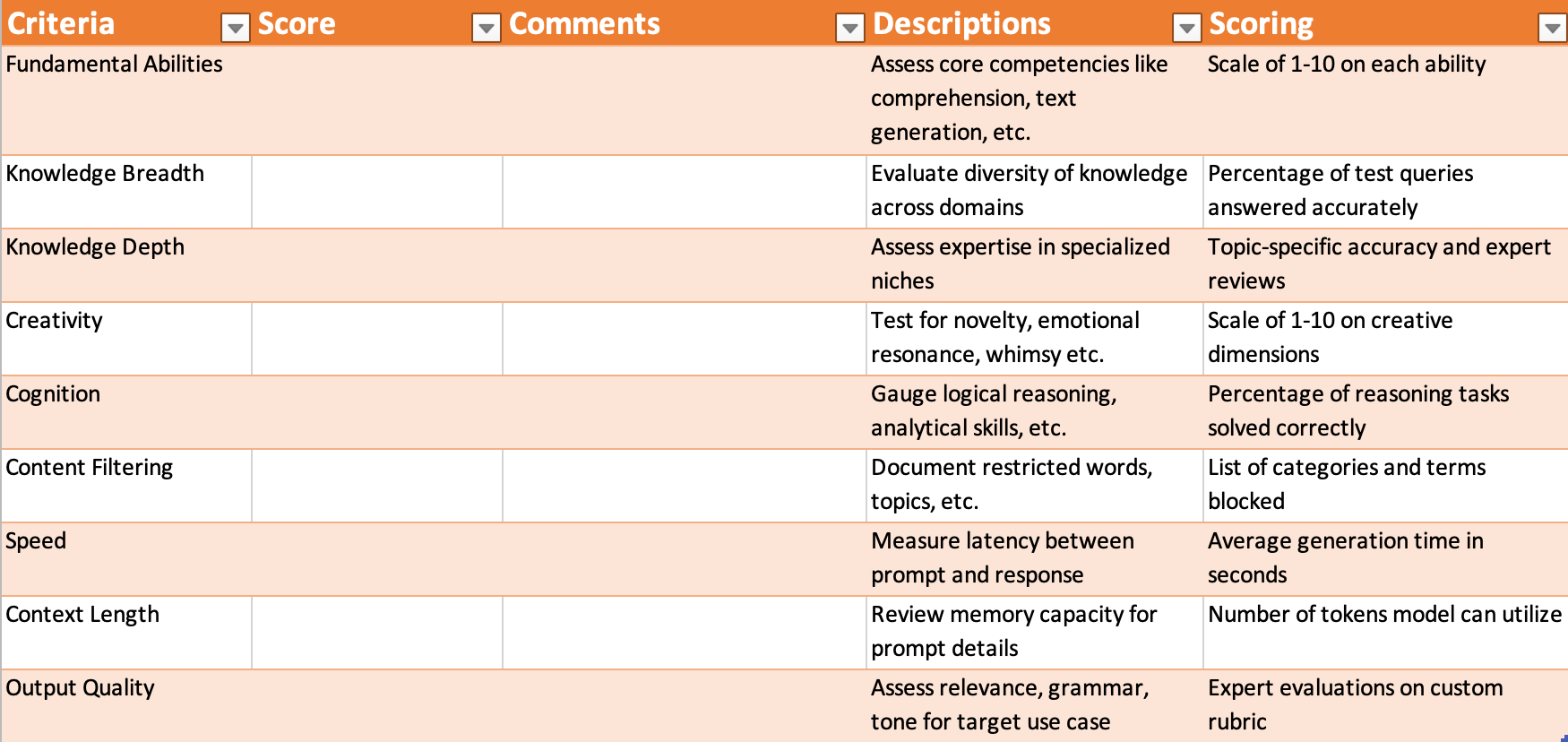
Aligned Benchmarking Scorecards Streamline LLM Selection
Creating matching benchmarking scorecards for tasks that match with LLMs makes model selection seamless:
Tailored Task Scorecards: First, develop scorecards customized to each use case that capture required capabilities, knowledge areas, output quality metrics, and content considerations. These profile the criteria for success.
Aligned LLM Scorecards: Then create corresponding scorecards for candidate LLMs, using parallel categories rated through comprehensive testing. This builds LLM profiles.
Cross-Referencing Needs and Abilities: With task needs and LLM abilities aligned in the scorecards, matching models to use cases becomes easy. Simply reference the benchmarked criteria.
Optimized Model Selection: Choosing LLMs based on benchmarked alignment between their specialized strengths and the target task's demands enables optimized pairing.
Here are two task scorecard options you may want to consider and build upon:
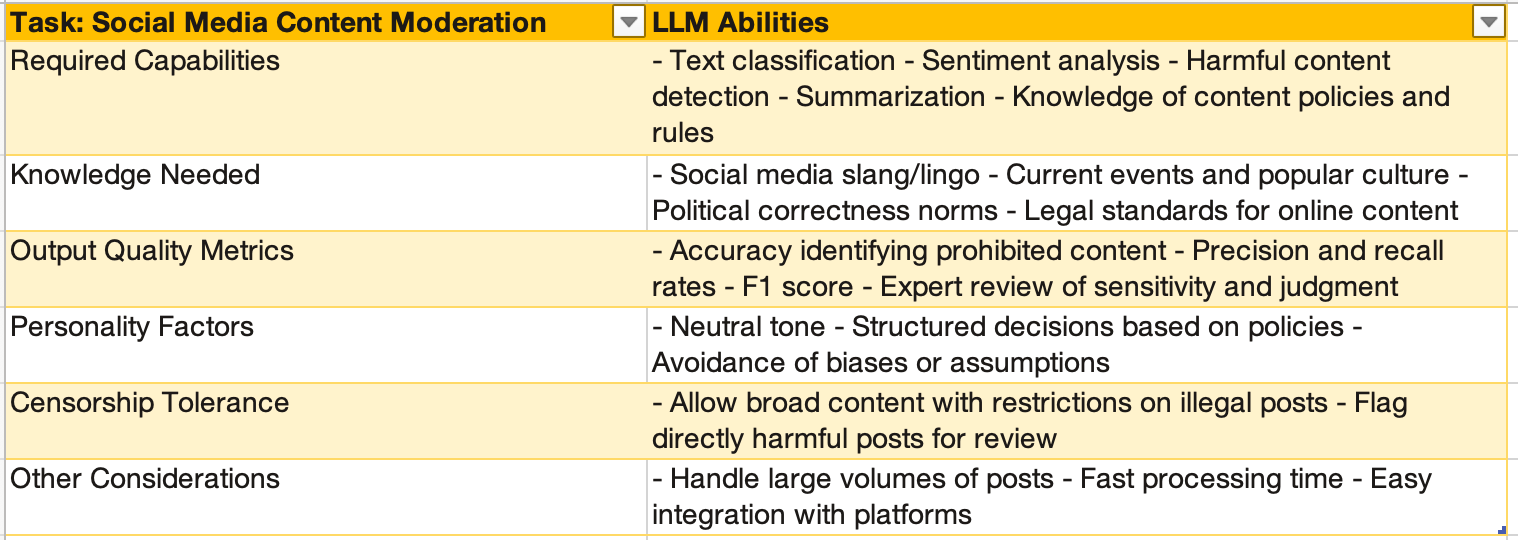
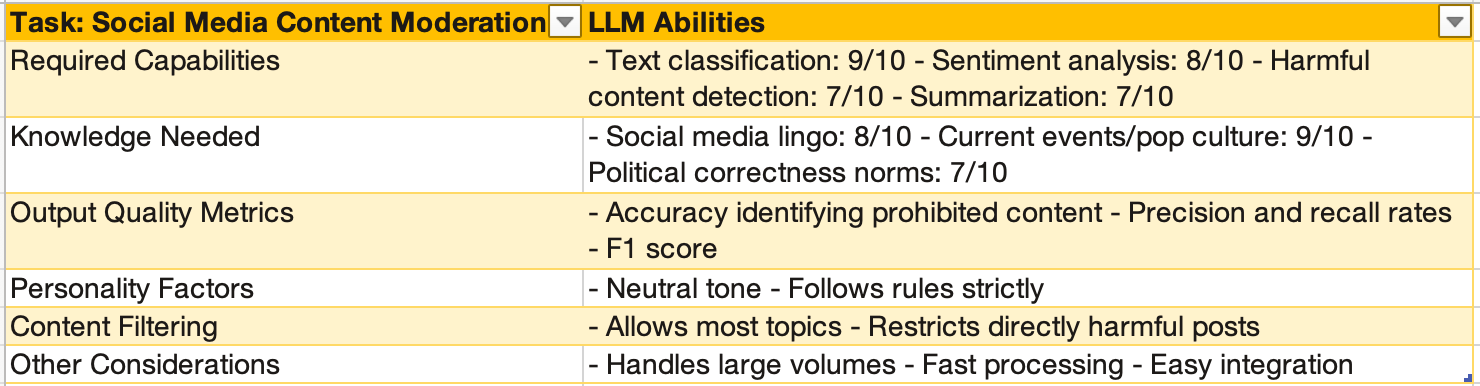
Scorecard alignment doesn't guarantee success but does allow efficient shortlisting of high-potential LLM candidates for further evaluation. Streamlining selection helps cut through today's dizzying options.
Benchmarking Guides Prompt Engineering Needs
An LLM's capabilities and limitations revealed through benchmarking will directly inform the prompt engineering requirements for a particular task:
- LLMs with lower scores for key criteria like reasoning or domain knowledge will need more extensive prompt programming to perform well on related tasks.
- Models with creativity gaps may demand lengthy prompt chains and examples to induce the desired creative output.
- LLMs lacking in contextual coherence call for prompt techniques to keep responses grounded.
- Imprecise language generation necessitates careful prompt crafting to hit the desired style and tone.
In essence, benchmarking illuminates where additional prompting must shore up an LLM's weaknesses for a given use case. Thorough evaluation provides a prompt engineering blueprint tailored to each model's specialized profile.
Just as benchmarking enables optimal model selection, it also reveals the prompt programming needed to maximize an LLM's talents while minimizing its shortcomings through careful prompting. Benchmark diligently to prompt efficiently.
Wrap-up: Quality Over Benchmarks
While various metrics exist for evaluating LLMs, what truly counts is the quality of the output in a real-world business context. As the LLM landscape continues to evolve, understanding the nuances of these models becomes increasingly vital for businesses aiming to leverage them effectively.
By adopting a structured approach that weighs fundamental abilities, knowledge, creative capacities, and cognitive skills, organizations can make more informed decisions when integrating LLMs into their workflows.
Businesses should move beyond perplexity and theoretical benchmarks to focused, hands-on testing of LLMs on their actual content. Understanding these models' specialized strengths and limits is essential to extracting value responsibly. Aligned scorecards and benchmarking to use case requirements enables optimized pairing. Pragmatic evaluation trumps universal metrics in guiding real-world LLM adoption.
Downloads
Download the free Excel worksheet below and make sure to customise for your organization or task.
