

Today, Facebook has released LLaMA, a set of four foundation models that range in size from 7 billion to 65 billion parameters. These models have been trained on at least 1 trillion tokens, significantly more than what is typically used at this scale, and they have outperformed some of the biggest names in the industry.
Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters.
— Guillaume Lample (@GuillaumeLample) February 24, 2023
LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B.
The weights for all models are open and available at https://t.co/q51f2oPZlE
1/n pic.twitter.com/DPyJFBfWEq
LLaMA-13B Outperforms OPT and GPT-3 175B on Most Benchmarks
LLaMA-13B has outperformed OPT and GPT-3 175B on most benchmarks. This is a significant achievement in the field of large language models and showcases the power of the LLaMA models. The success of LLaMA-13B on these benchmarks is a testament to the hard work and dedication of the Facebook team.
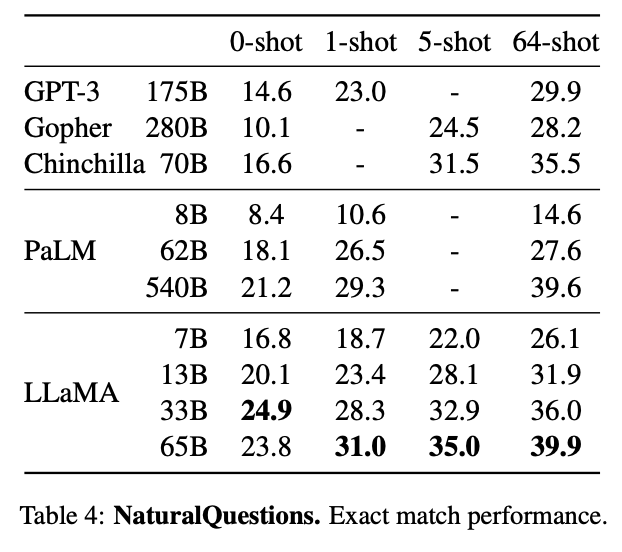
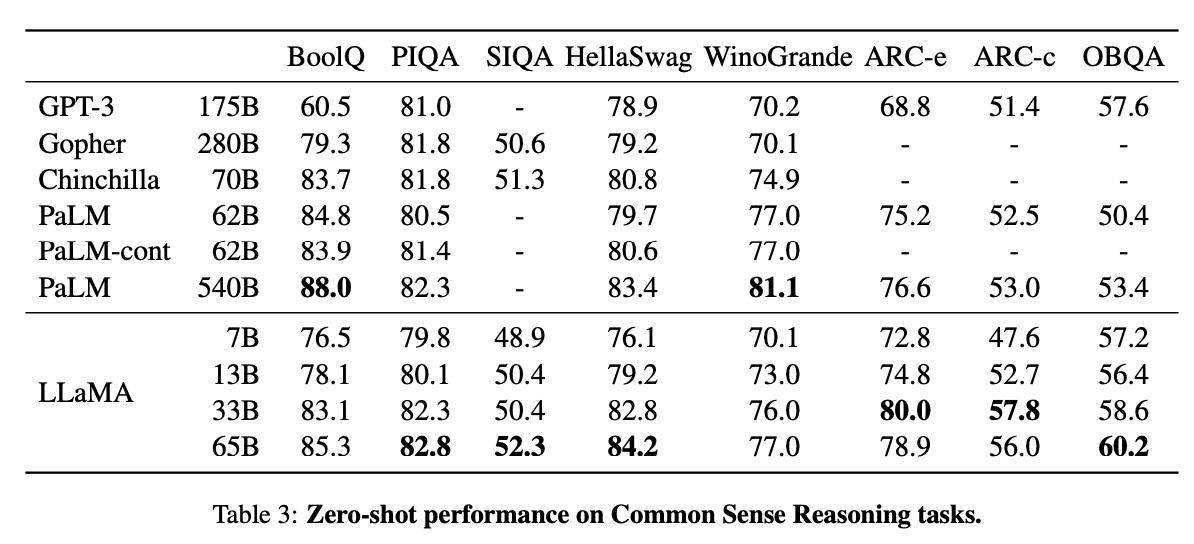
LLaMA-65B is Competitive with Chinchilla 70B and PaLM 540B
LLaMA-65B is also competitive with Chinchilla 70B and PaLM 540B. Unlike Chinchilla, PaLM, or GPT-3, the LLaMA models were only trained using publicly available datasets, making the work compatible with open-sourcing and reproducible. This is a significant advantage over existing models, as most of them rely on data that is either not publicly available or undocumented.
LLaMA Models Trained on 1T Tokens
All of the LLaMA models were trained on at least 1 trillion tokens, which is significantly more than what is typically used at this scale. This extensive training has enabled the models to achieve impressive performance on various benchmarks.
7B Model Improving After 1T Tokens
Interestingly, even after being trained on 1 trillion tokens, the 7B model was still improving. This shows that there is still room for growth and improvement in the LLaMA models, and the Facebook team is likely to continue refining and perfecting them in the future.
LLaMA-65B Outperforms Chinchilla 70B and PaLM 540B on Common Sense Reasoning, Closed-book Question Answering, and Reading Comprehension
On Common Sense Reasoning, Closed-book Question Answering, and Reading Comprehension, LLaMA-65B outperforms Chinchilla 70B and PaLM 540B on almost all benchmarks. This is a remarkable accomplishment and demonstrates the advanced capabilities of the LLaMA models.
LLaMA-65B Outperforms Minerva-62B on GSM8k
LLaMA-65B has also outperformed Minerva-62B on GSM8k, even though it has not been fine-tuned on any mathematical dataset. This is a testament to the versatility of the LLaMA models and their ability to perform well on a wide range of tasks.
LLaMA-62B Outperforms PaLM-62B and PaLM-540B on Code Generation Benchmarks
On code generation benchmarks, LLaMA-62B outperforms cont-PaLM (62B) as well as PaLM-540B. This is a significant achievement and highlights the potential of the LLaMA models for use in a variety of applications.
LLaMA-I Outperforms Flan-PaLM-cont (62B) on MMLU
The Facebook team also briefly tried instruction finetuning using the approach of Chung et al. (2022). The resulting model, LLaMA-I, outperforms Flan-PaLM-cont (62B) on MMLU and showcases some interesting capabilities in the field of instruction-based models and their potential for use in a variety of applications. This is a promising development in the field of large language models and provides evidence that the LLaMA models are capable of performing well on a wide range of tasks.
Takeaway
The release of LLaMA represents a significant milestone in the field of large language models. The models have outperformed some of the biggest names in the industry, and their success on various benchmarks highlights their advanced capabilities and potential for use in a variety of applications. The fact that the models were trained on publicly available datasets makes them compatible with open-sourcing and reproducible, and the continued improvement of the 7B model after 1 trillion tokens shows that there is still room for growth and improvement in the LLaMA models. The Facebbok team is likely to continue refining and perfecting the models in the future, and the release of LLaMA is sure to have a significant impact on the field of large language models.
Read the full Facebook / Meta release here


Request Access Here



Comments