
The Generative AI Revolution: An Introduction to Retrieval Augmented Generation
The release of ChatGPT in November 2022 sparked tremendous excitement about the potential for large language models (LLMs) like it to revolutionize how people and organizations use AI. However, in their default form, these models have limitations around working with custom data.
This is where the idea of retrieval augmented generation (RAG) comes in. RAG is a straightforward technique that enables LLMs to dynamically incorporate external context from databases. By retrieving and appending relevant data to prompts, RAG allows LLMs to produce high-quality outputs personalized to users' needs.
Since ChatGPT burst onto the scene, interest in RAG has skyrocketed. Organizations want to leverage powerful models like ChatGPT while also equipping them with proprietary company data and knowledge. RAG offers a way to get the best of both worlds.
In this article, we will provide an overview of RAG and its applications. While the core principle is simple, RAG unlocks a breadth of new possibilities for generating customized, grounded content with LLMs. Join us as we explore this versatile technique fueling the next evolution of AI!
What is Retrieval Augmented Generation (RAG)? A Simple Explanation
When using a large language model (LLM) like ChatGPT, you can provide additional context by including relevant information directly in the prompt. For example, if you paste the text of a news article into the prompt, ChatGPT can use that context to generate a timeline of events.
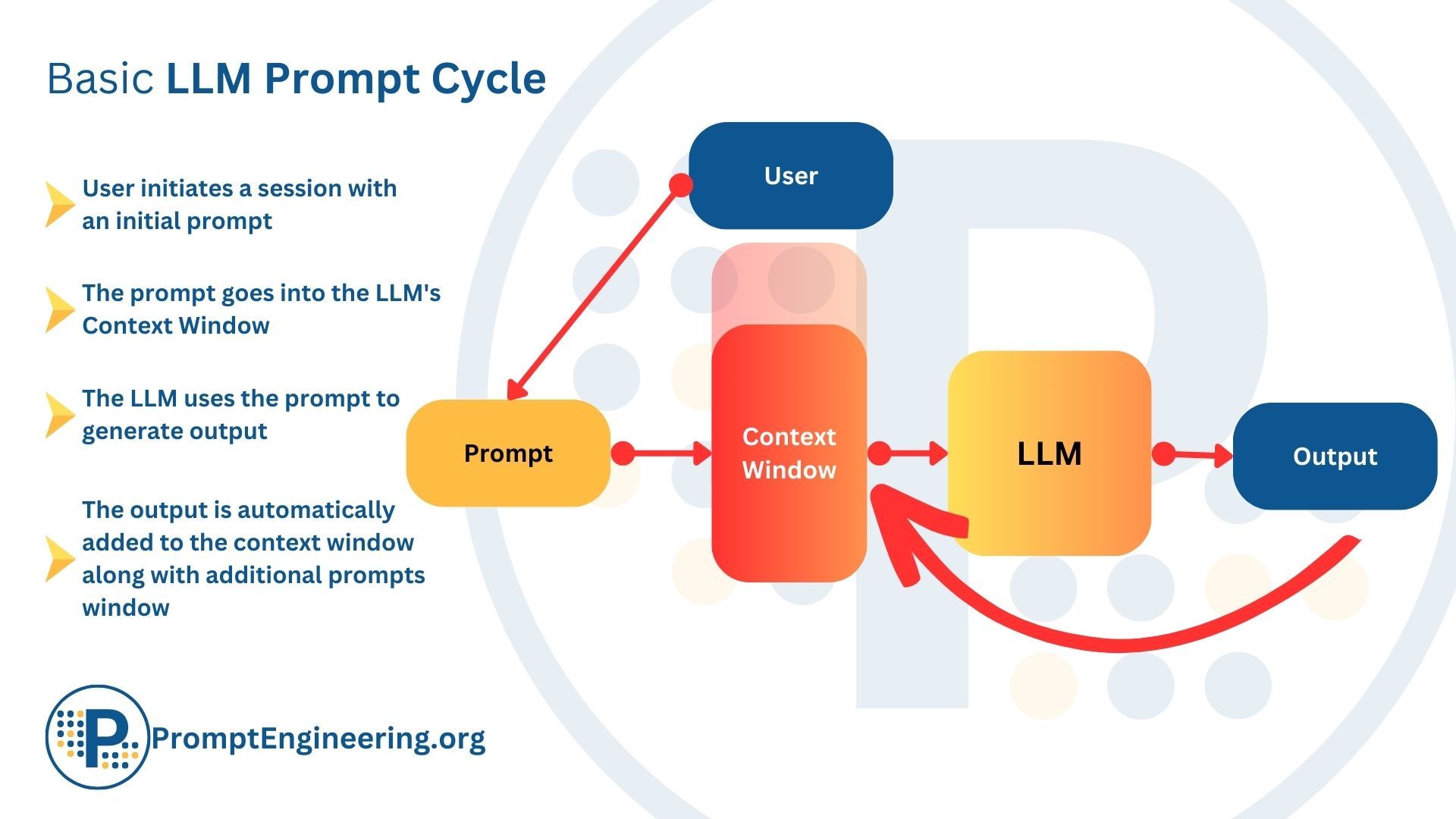
Retrieval augmented generation (RAG) works similarly but automates this process using a vector database. Instead of manually adding information to the prompt, relevant data is automatically retrieved from the database and combined with the original prompt.

Here's a simple step-by-step example:
- You input an initial prompt to the system, such as "Please summarize the key events in the news recently."
- Behind the scenes, the system searches a vector database full of up-to-date news articles and finds relevant hits based on semantic similarity.
- These retrieved articles are combined with the original prompt to create an expanded prompt with additional context.
- This new "augmented" prompt looks something like this: "Please summarize the key events in the news recently. Yesterday, there was a 7.2 earthquake in Turkey. The day before, NASA launched a new spaceship..."
- The expanded prompt is fed to the LLM, which now has the context to generate a useful summary grounded in real data.
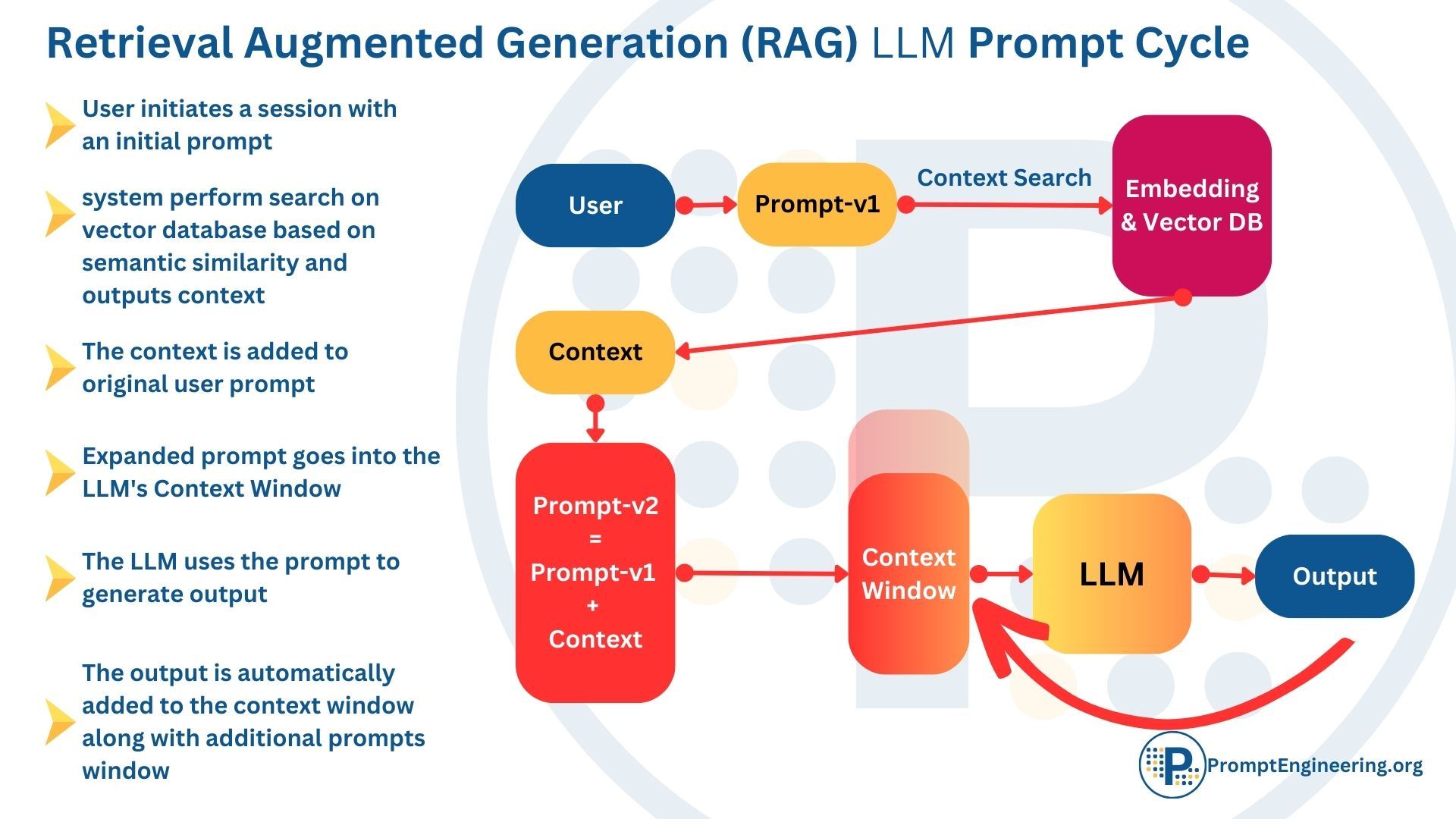
So in essence, RAG automatically enhances prompts by extracting relevant information from a database. This provides LLMs with the external knowledge they need to produce high-quality, accurate content beyond their default capabilities. The vector search does the work of finding contextual data so you don't have to!
Overview of large language models (LLMs) and their limitations
Large language models (LLMs) like OpenAI's ChatGPT and Anthropic's Claude represent some of the most advanced AI systems created to date. Powered by deep learning on massive text datasets, these models are capable of incredibly fluent and human-like conversational abilities. However, beneath their brilliance lie several critical flaws:
Brilliance and flaws of LLMs like OpenAI's ChatGPT and Anthropic's Claude
LLMs like ChatGPT and Claude exhibit remarkable language proficiency. They can engage in open-ended dialogue, answer follow-up questions, admit mistakes, challenge incorrect premises, and reject inappropriate requests. This natural conversational ability gives the illusion of human-level intelligence.
However, LLMs have serious limitations rooted in their training methodology. While they have seen a massive breadth of language data, it is ultimately fixed and finite. This "closed world" of pre-training constrains real-world applicability.
Key drawbacks: static nature, lack of domain knowledge, opacity, high costs
Specifically, LLMs suffer from four main drawbacks:
- Static nature - LLMs are "frozen in time" based on their pre-training data cutoff date. They lack continuously updated knowledge.
- Lack of domain knowledge - LLMs are generalized models without specialized expertise. They do not incorporate proprietary business data.
- Black box opacity - The inner workings of LLMs are opaque. The reasoning behind their outputs is unclear.
- High training costs - Developing LLMs requires massive computational resources, datasets, and ML expertise.
Consequences: Inaccuracy and hallucination in real-world applications
These deficiencies significantly impact LLMs' accuracy when deployed in production applications. Without up-to-date knowledge or domain-specific data, LLMs struggle with context-dependent tasks.
LLMs often "hallucinate" plausible but incorrect answers. Their outputs cannot be fully trusted or audited without transparency into their reasoning process. Addressing these limitations is essential for creating safe and robust LLM applications.
Introducing retrieval augmented generation (RAG) as a solution
Retrieval augmented generation (RAG) offers a promising approach to enhancing LLMs and overcoming their limitations.
Definition and capabilities of RAG
RAG combines a language model with a retrieval system to provide relevant context for text generation. At query time, a RAG system retrieves grounding documents from a database and feeds them to the LLM to inform its output.
RAG systems can dynamically bring in up-to-date information, domain-specific data, and other sources to reduce hallucination risks and improve accuracy.
How RAG addresses limitations of LLMs
RAG directly tackles the core weaknesses of LLMs:
- Adds recency through real-time database updates
- Incorporates domain knowledge lacking in pre-training
- Enables transparency by retrieving source documents
- Leverages existing LLMs without costly retraining
RAG is the preferred approach over alternatives
Compared to creating a new LLM or fine-tuning an existing one, RAG is lower cost, lower risk, and more flexible. It does not require massive datasets or compute. The retrieval system can be optimized independently of the core LLM. For these reasons, RAG has emerged as a preferred technique.
RAG combines the strengths of LLMs and search to augment language models dynamically. It provides a pathway for developing performant, safe AI applications grounded in real data.
Semantic search and vector databases
Semantic search and vector databases are key enabling technologies for retrieval augmented generation.
Creating vector representations of data
The first step is to convert data into numerical vector representations that encode semantic meaning. This is done via embedding models like BERT or GPT-3.
These models transform text, images, audio, and other data into high-dimensional vectors. Vectors are numerical arrays that represent the conceptual significance of the data.
Loading vectors into a database for fast retrieval
These vector embeddings can then be loaded into a specialized database optimized for ultrafast similarity search.
Popular options include FAISS, Milvus, Pinecone, and Weaviate. These vector databases allow querying billions of data points in milliseconds.
Updating database in real-time
A key advantage of vector databases is that they can be updated continuously with new data.
The database can ingest and index streaming vectors in real time. This means the results returned to the LLM are always fresh and relevant.
For example, a customer support bot could update its knowledge base hourly with new product specs or inventory data. This dynamical retrieval is impossible with static LLM training.
By combining semantic vectors and fast retrieval, RAG systems can provide LLMs with constantly refreshed, domain-specific knowledge to reduce hallucination risks.
Using databases for natural language queries
Vector databases excel at interpreting natural language queries to return the most useful results.
Translating user queries into vector representations
First, the user's question or request is converted into a vector representation via an embedding model.
This creates a semantic vector that captures the meaning behind the natural language query.
Database returning most relevant results
This vector is then used to query the database, which retrieves the vectors most similar to the input based on cosine similarity.
So rather than matching keywords, the database identifies results based on semantic closeness to the query vector.
Providing results to LLM via context window
These retrieved results are then provided to the LLM's context window, giving it relevant examples and documents to guide text generation.
The LLM integrates these context documents into its output, reducing hallucination risk by grounding its responses in data.
Overall, the natural language capabilities of vector databases allow them to interpret free-form user queries. When combined with an LLM, this enables more natural and accurate human-AI interaction.
Reducing hallucinations with relevant data
A core benefit of RAG is its ability to reduce an LLM's hallucinations by supplying relevant contextual data.
LLM generates responses using the provided context
The dynamically retrieved documents give the LLM key facts to reference when formulating its response. It can incorporate details and terminology from the context window into its output.
Grounding responses in factual information
This grounds the LLM's responses in factual sources rather than having it rely solely on its pre-trained knowledge. Referencing supporting documents enables more accurate, context-aware replies.
Hybrid search for semantics and keywords
Some RAG implementations combine semantic and keyword searches for retrieval. This leverages semantic similarity while also matching key terms.
Hybrid search ensures the context window contains on-topic documents with relevant details. This further reduces the chance of hallucination.
By providing current, targeted data to augment the LLM, RAG systems can keep responses factual and avoid misleading fabricated content. The context window acts as a grounding mechanism to enhance accuracy.
Performance boost for GenAI applications
RAG provides significant performance improvements for real-world GenAI applications compared to using an LLM alone.
Higher accuracy and relevance
By grounding the LLM in external data, RAG increases the accuracy and relevance of generated text. Responses become more precise and contextualized to the user's query.
RAG reduces cases of inappropriate or nonsensical outputs by keeping the LLM focused on pertinent facts.
Superior end-user experience
This increased accuracy translates directly into a superior experience for end users. They receive high-quality responses tailored to their needs rather than generic or inaccurate text.
Interfaces powered by RAG feel more natural, intelligent, and human-like by incorporating recent information and domain knowledge. RAG moves GenAI apps beyond basic chatbots.
In summary, RAG supercharges GenAI applications by dynamically enhancing their capabilities. The integration of retrieval makes outputs more accurate, useful, and aligned with user expectations. This creates a smoother, more effective end-user experience.
Addresses Limitations Effectively
Retrieval augmented generation directly tackles two core weaknesses of standard large language models - lack of recent data and domain-specific knowledge.
Provides Recency Through Real-Time Updates
RAG enables real-time, continual updates to the information available to the LLM via the vector database. New data can be added seamlessly.
This ensures the model has access to the most current information rather than relying solely on its static pre-training. Recency improves accuracy for timely queries.
Adds Domain Specificity Lacking in LLM
Additionally, RAG augments the LLM's general knowledge with domain expertise by retrieving relevant data from the vector database.
This domain-specific context, such as user data or product specs, adds specialized knowledge the LLM lacks. The database provides the tailored data needed for the application.
In summary, RAG specifically targets the core deficiencies of LLMs in a dynamic, low-cost manner. By combining retrieval with generation, it adapts language models to be effective in real-world contexts requiring recent, specialized knowledge.
Cost and Risk Reduction
Compared to alternatives like creating a new LLM or fine-tuning an existing one, retrieval augmented generation provides greater feasibility, lower costs, and reduced risks.
More Feasible Than Creating or Fine-Tuning LLM
Building a new large language model requires massive datasets, computing power, expertise, and ongoing maintenance. Fine-tuning is also resource-intensive.
In contrast, RAG leverages existing LLMs and simplifies scaling via the modular retrieval system. This makes deployment more attainable.
Prompt Engineering Insufficient Alone
While prompt engineering can help, it cannot provide the dynamic updating and contextual grounding of RAG. Relying solely on prompts is insufficient.
Quick and Low-Risk Integration
RAG systems like Pinecone allow rapid setup and iteration. The retrieval database can be optimized and expanded safely without impacting the core LLM.
In summary, RAG delivers enhanced performance while lowering barriers. By augmenting LLMs efficiently, it reduces costs, complexity, and risks - facilitating real-world usage.
Wrapping Up
Retrieval augmented generation represents an enormous leap forward in leveraging the strengths of large language models for real-world applications. By seamlessly integrating external context, RAG enables LLMs to produce outputs that are customized, relevant, and grounded in facts.
As we have explored, RAG tackles the core weaknesses of LLMs - their static nature, lack of specificity, and opacity. Vector databases provide dynamically updated domain knowledge to reduce hallucinations and improve accuracy.
Compared to costly alternatives, RAG is scalable and low-risk. The modular architecture allows iterating on the retrieval component without retraining models. Overall, RAG delivers substantial gains in performance, capability, and usability over unaugmented LLMs.
RAG stands to have a widespread impact across sectors as diverse as healthcare, education, e-commerce, and more. Any field that relies on language and knowledge is ripe for enhancement through RAG techniques. This technology marks a major milestone in making real-world AI more usable, trustworthy, and beneficial.
As RAG capabilities grow more robust, so too will the practical utility of large language models. By seamlessly synthesizing retrieval and generation, RAG truly unlocks the power and potential of LLMs. Their integration paves the way for more creative, capable, and contextual AI applications.