

Since the launch of ChatGPT, businesses and enterprises have been exploring ways to implement large language models into their organizations. However, for non-technical stakeholders, it can be challenging to grasp how all the components of generative AI fit together into a cohesive system.
To bridge this gap, this article introduces the Generative AI Tech Stack - a conceptual model for understanding the layers that comprise a complete generative AI solution. By structuring the stack into logical components, we aim to provide executives, managers, and other business leaders an accessible overview of how the parts interconnect.
The Generative AI Tech Stack model is ordered from the bottom up, beginning with the foundational large language models that power AI text generation. It then adds layers like databases, integration, and orchestration that augment the AI with real-world data and services. At the top sit user applications and interfaces that deliver customized experiences powered by the AI stack.
While abstracted, the stack presents the core building blocks of an enterprise-ready generative AI system. The goal is to demystify how seemingly magical text AI can be harnessed as a practical business tool. With the stack as a guide, leaders can better grasp generative AI's capabilities and limitations to plan effective strategies grounded in reality.
By contextualizing the technology within this understandable framework, the Generative AI Tech Stack aims to spark informed discussions about AI's immense possibilities and responsible implementation across organizations.
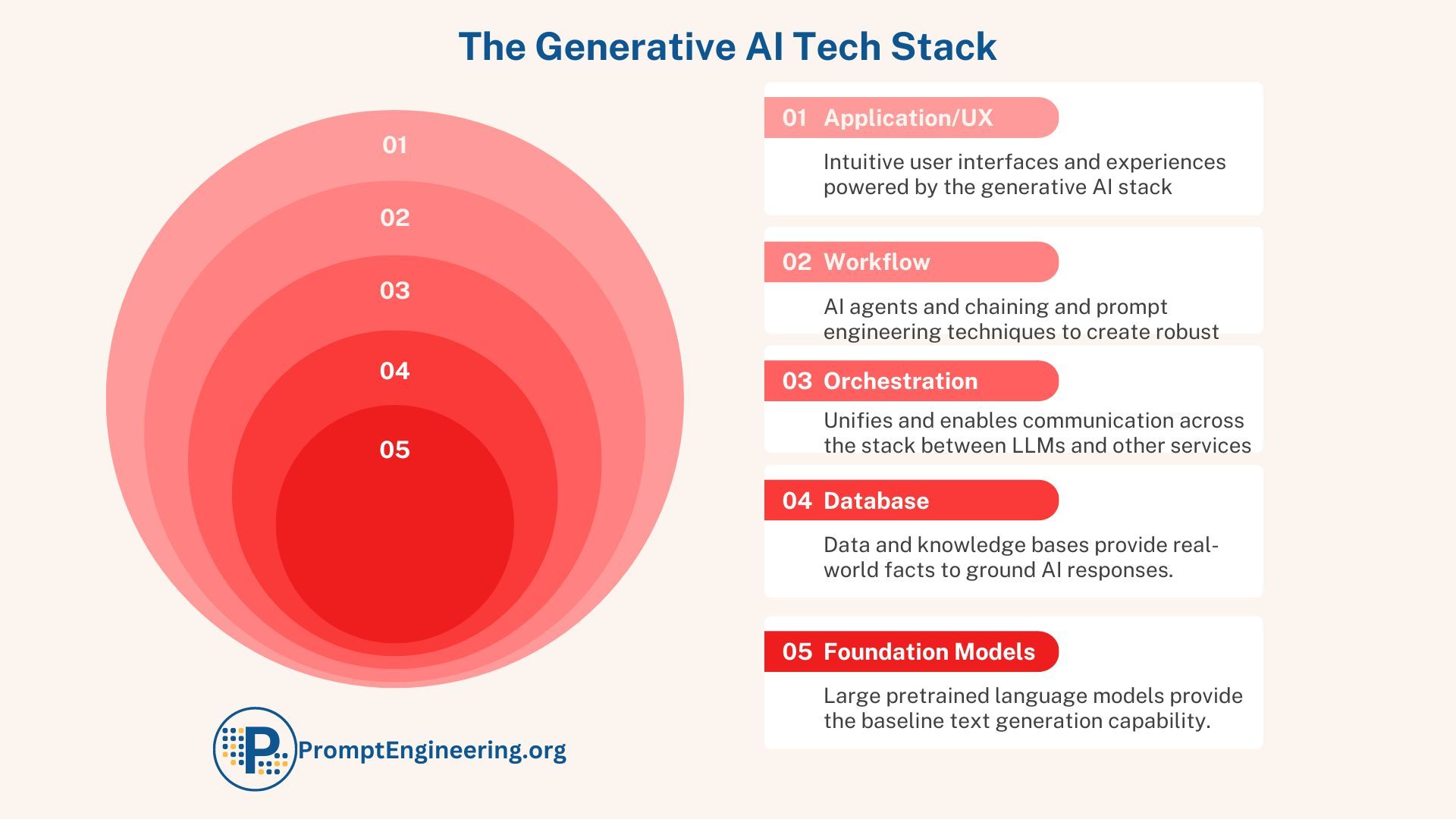
Foundational Models: LLMs Underpin the Generative AI Revolution
At the base of the Generative AI Tech Stack are Large Language Models (LLMs) like GPT-3 and Anthropic's Claude. These neural networks with billions of parameters have sparked the generative AI revolution by producing remarkably human-like text.
LLMs are trained on massive text datasets to deeply understand the nuances of natural language, including grammar, semantics, and how context influences meaning. This knowledge allows LLMs to generate coherent, sensible responses to prompts, powering applications like chatbots, content generation, and semantic analysis.
However, raw unchecked LLMs can sometimes hallucinate false information or lack necessary real-world knowledge. This demonstrates the need for additional components in the full generative AI stack.
LLMs serve as foundation models - general-purpose models pre-trained on huge datasets. Foundation models like GPT-3 and DALL-E establish a strong baseline capability in text and image generation respectively.
To customize foundation models for specific domains, they can be fine-tuned with relevant datasets. This aligns their outputs to specialized tasks like answering product queries, generating code, or leveraging proprietary APIs.
These ever-advancing foundation models drive breakthroughs across modalities in generative AI. They provide the critical starting point that the rest of the tech stack builds upon to create tailored, useful applications.
Customization vs Convenience: Foundation Model Source Options
When implementing the Foundational Models layer, one of the first decisions is whether to utilize open-source or closed-source foundation models or a combination.
Open-source models like GPT-NeoX allow full customization and can be trained on sensitive data where privacy is critical. However, open source requires setting up infrastructure and compute to run the models.
Closed source models like GPT-3 offer cutting-edge capability accessible via API keys and subscriptions, without infrastructure worries. But customization is limited and SLAs must be evaluated.
Weighing the benefits of innovation versus control, many choose hybrid strategies employing both major closed-source providers and open-source models fine-tuned for niche tasks. Upfront thought to open vs. closed tradeoffs clarifies options at the start when architecting for scale.
Database/Knowledge Base Layer: Enable Contextual Responses
On top of the raw power of foundation models sits the Database/Knowledge Base layer. This component allows grounding of generative AI in real-world facts and data.
Databases store organized structured data like customer profiles, product catalogues, and transaction histories. This data provides the critical context needed for the generative AI to produce useful, personalized responses.
For example, a customer service chatbot can use customer purchase history from a database to make relevant product suggestions. A generative content tool can pull current pricing data to autocomplete promotions in an email.
Knowledge bases codify facts, rules, and ontology to augment the world knowledge in foundation models. They provide an evolving memory that prevents repeating mistakes or hallucinating false information.
To leverage this knowledge, databases must support efficient vector similarity searches. This allows for linking related concepts and quickly retrieving relevant context.
The Database/Knowledge Base layer enables generative AI to be truly contextual. It ensures responses are grounded in facts rather than pure imagination, delivering accurate information tailored to the user.
Orchestration Layer Combines Data and Services
Sitting above the Database layer is the Orchestration Layer. This component seamlessly combines relevant data and services into the context of generative AI.
The orchestration layer pulls data from diverse databases and APIs in real time to enrich the context. This data augmentation provides the models with customized information for highly relevant responses.
For instance, an e-commerce recommendation tool could retrieve user browsing history, inventory, and pricing data from various systems. Integrating this data ensures the most useful, in-stock products are suggested.
The orchestration layer also handles any required data transformations into the vector format needed by generative AI. Unstructured data like emails or logs can be encoded as usable vectors.
Additionally, the layer invokes any external APIs to further enrich the context as needed. API calls for validation, authentication, or business logic inject context before querying the AI.
By smoothly orchestrating data, transformations, and services, the Orchestration Layer tailors the context to each user situation. This powers the Generative AI Tech Stack to provide personalized, context-aware responses.
Workflow Layer Creates Business Value
Sitting on top of the Integration Layer is the Workflow layer. This logical layer coordinates invoking the optimal generative AI models and components to complete a given workflow.
Within the Workflow Layer, concepts like chaining, guardrails, retrieval, reranking, and ensembling combine to achieve robust outcomes from generative AI:
- AI Agents: Goal-driven LLM instances with remarkable reasoning capacities
- Chaining sequences of multiple LLMs and additional modules into an orchestrated workflow to reliably generate the desired output.
- Generative AI Networks: GAIN is a Prompt Engineering technique to solve complex challenges beyond the capabilities of single agents.
- Guardrails monitor LLM responses and steer them back on track if errors or unsafe content are detected.
- Retrieval grounds the LLM in facts by retrieving relevant knowledge from databases as needed.
- Reranking generates multiple candidate responses from the LLM which are reranked to select the best, most relevant one.
- Ensembling combines outputs from multiple LLMs to improve consistency and accuracy over any single model.
 Sunil Ramlochan - Enterprise AI Specialist
Sunil Ramlochan - Enterprise AI Specialist

By thoughtfully composing workflows from reusable primitives, the Workflow Layer creates generative AI pipelines tailored to specific use cases. Workflows codify best practices around security, accuracy, and mistake recovery for real-world reliability.
For instance, a content moderation workflow could use chaining, human validation steps, and templated prompts to enforce community guidelines. The workflow acts as a full pipeline with guardrails.
By coordinating models and techniques in the Workflow layer, the system can complete complicated workflows end-to-end. Rather than isolated models, chained generative AI components produce results users can trust.
For example, a moderation system could use chaining, guardrails, and ensembling to reliably generate content that meets safety guidelines. By orchestrating multiple models with oversight, the risk of unsafe or nonsensical outputs is greatly reduced.
The Workflow layer represents one of two areas in the stack where main human interaction occurs. Prompt engineers will interface with the Workflow layer regularly to design and optimize workflows by combining different generative AI models and techniques.
By testing out various orchestrations of chaining, guardrails, reranking, etc., prompt engineers can iteratively improve the reliability and accuracy of outcomes for different tasks. They will reuse components like LLMs in novel combinations, tuning hyperparameters as needed.
The logic flows conceived in the Workflow layer then become reusable modules that can be invoked from the Application layer above. Rather than starting workflows from scratch, developers at the application layer can simply leverage the pre-built workflows as reliable generative AI services for common tasks.
The workflows conceived in the Workflow layer then become reusable modules that can be invoked from the Application layer above via API endpoints. Rather than starting workflows from scratch, developers at the application layer can simply leverage the pre-built workflows as reliable generative AI services for common tasks by calling their API endpoints.
By intelligently combining the powers of different generative AI building blocks, the Workflow layer creates robust systems greater than the sum of their parts. In essence, the Workflow Layer takes raw AI models and combines them into assemblies that meet production needs. It raises generative AI from flexible components to structured processes.
UX /Application Layer Brings the Power of AI to Everyday Users
At the top of the Generative AI Tech Stack sits the Application or the User Experience (UX) layer. This tier focuses on seamlessly integrating generative AI to craft intuitive user interfaces.
Early generative AI applications mainly relied on text prompts and responses. But the Application layer opens up new modalities like voice, vision, and conversational UIs.
For example, an application could incorporate graphical widgets and menus alongside text interactions. Users could speak prompts and commands rather than typing them. Apps can leverage image recognition to interpret visual inputs.
Chatbots and conversational agents represent some initial manifestations of these more natural UX approaches. These tools allow users to interact conversationally with an app, similar to speaking with a human.
As generative AI advances, the Application layer will focus on making interactions as seamless and intuitive as possible. The UX should not compromise user experience when leveraging AI capabilities.
UX design bridges the gap between humans and machines, aiming to craft inclusive, user-centred applications. Considering UX early in the development process helps ensure apps provide satisfying experiences that deliver true utility to end users.
By focusing on natural interfaces beyond just text, the Application layer realizes the full potential of generative AI. Intuitive design allows end users to benefit from AI in the most accessible, meaningful ways possible.
Navigating Infrastructure and Services Across the Stack
While the Generative AI Tech Stack provides a logical view of the core components, each layer has its own complexities related to infrastructure, software, and vendors.
The optimal database systems, orchestration platforms, and model hosting services differ across layers. There are various commercial and open-source solutions to evaluate at each level, with considerations around features, scalability, and costs.
For example, the Foundation Models layer requires a specialized model serving GPU infrastructure for optimal performance and cost efficiency. The Integration layer may leverage messaging systems like Kafka along with internal API gateways.
Choosing whether to deploy on-premises or use cloud-based services is also a consideration for each layer. The right deployment architecture will depend on IT strategies, budgets, and regulatory requirements.
Integrating best-of-breed components from multiple vendors increases challenges around unified data schemas, security, monitoring, and skill gaps. The interfaces between layers must be robust and well-governed.
Essentially, while the Generative AI Tech Stack provides the logical blueprint, mapping stack components to real-world infrastructure and platforms remains an open design challenge. Business needs, existing systems, and future strategies help determine optimal vendor and deployment decisions.
As the space matures, we expect new solutions to emerge offering more integrated cross-layer platforms and automated tooling for managing AI infrastructure complexity. But for now, assembling the right combination of providers and cloud services for each layer involves a thorough analysis of diverse options and tradeoffs.
Looking at the Model Critically: Limitations and Open Questions
While the Generative AI Tech Stack presents a useful conceptual model, it is an abstraction that inevitably simplifies some nuances and glosses over certain limitations. As with any technology framework, it is important to think critically about the model's assumptions and consider areas warranting further examination.
As companies move from AI experiments towards production deployments, the technology and best practices will continue rapidly evolving. The introduction of new techniques could shift the stack architecture going forward. Maintaining a critical perspective helps us build on the model prudently.
Here are some key limitations to consider with this (or any other) Generative AI Tech Stack model:
- It's a conceptual/logical model - the real-world implementation may differ significantly based on the specific technology choices and architectures used. The model simplifies complex, nuanced technical details.
- There could be debate about the layer boundaries - some components could span multiple layers, or additional layers may need to be defined. The mapping is not one-to-one.
- It focuses on the AI/ML pipeline - but robust infrastructure, security, governance, and operational processes are also key in enterprise AI systems. The model mainly highlights the core ML components.
- New innovative layers or architectures may emerge - the stack represents common patterns today but the technology is rapidly evolving. New best practices could augment or replace parts of the stack.
- It prioritizes modular flexibility - but tight integration of layers also has advantages. The balance between modular loose coupling vs tight cohesion is worth examining.
- Adopting all layers may be overkill for some focused use cases - simplifying the stack is reasonable when appropriate. Not every component is mandatory.
- The stack alone doesn't address business challenges like stakeholder alignment, managing change, or measuring value. Real-world success depends on both technical and human/process factors.
Overall the model provides a solid starting point to conceptualize a generative AI architecture. But as with any abstraction, it has limitations. The stack should be seen as a framework for discussion rather than a strict prescription. As we gain more practical experience, the stack and best practices will certainly continue to evolve.

Comments