
Module 5: Addressing AI's Limitations and Risks
Lesson 5.1: Technical Barriers to Adoption
1. Introduction
Welcome to Module 5. Up to this point in your learning journey, we have likely discussed the immense potential of Artificial Intelligence to transform industries, automate drudgery, and create new value. It is easy to look at the headlines and assume that AI is a "plug-and-play" solution—a software update that can simply be installed to instantly modernize an organization.
However, the reality of implementing Generative AI (GenAI) and Artificial Narrow Intelligence (ANI) is far more complex. We are currently in a phase where the promise of the technology often outpaces the readiness of the environment it is entering. Just as a Formula 1 engine cannot simply be dropped into a vintage car without destroying the transmission, modern AI models cannot easily run on the aging technical foundations of many of our most critical institutions.
This lesson focuses on the Technical Barriers to Adoption. We will move beyond the marketing hype to understand the tangible, physical, and structural hurdles that organizations face. We will explore why the "old" computer systems (legacy infrastructure) that run our banks and hospitals actively fight against new AI tools. We will examine the critical shortage of human expertise—the "skills gap"—that leaves many powerful tools sitting on the shelf. Finally, we will break down the massive computational costs required to run these models, explaining why the hardware involves far more than just buying a new laptop.
By the end of this lesson, you will understand why a company cannot simply "turn on" AI over the weekend. You will appreciate the massive industrial machinery required to generate even a single sentence of text and understand the strategic investments required to overcome these hurdles.
Slides







Explainer Video
2. Core Concepts
2.1 The Legacy Infrastructure Challenge
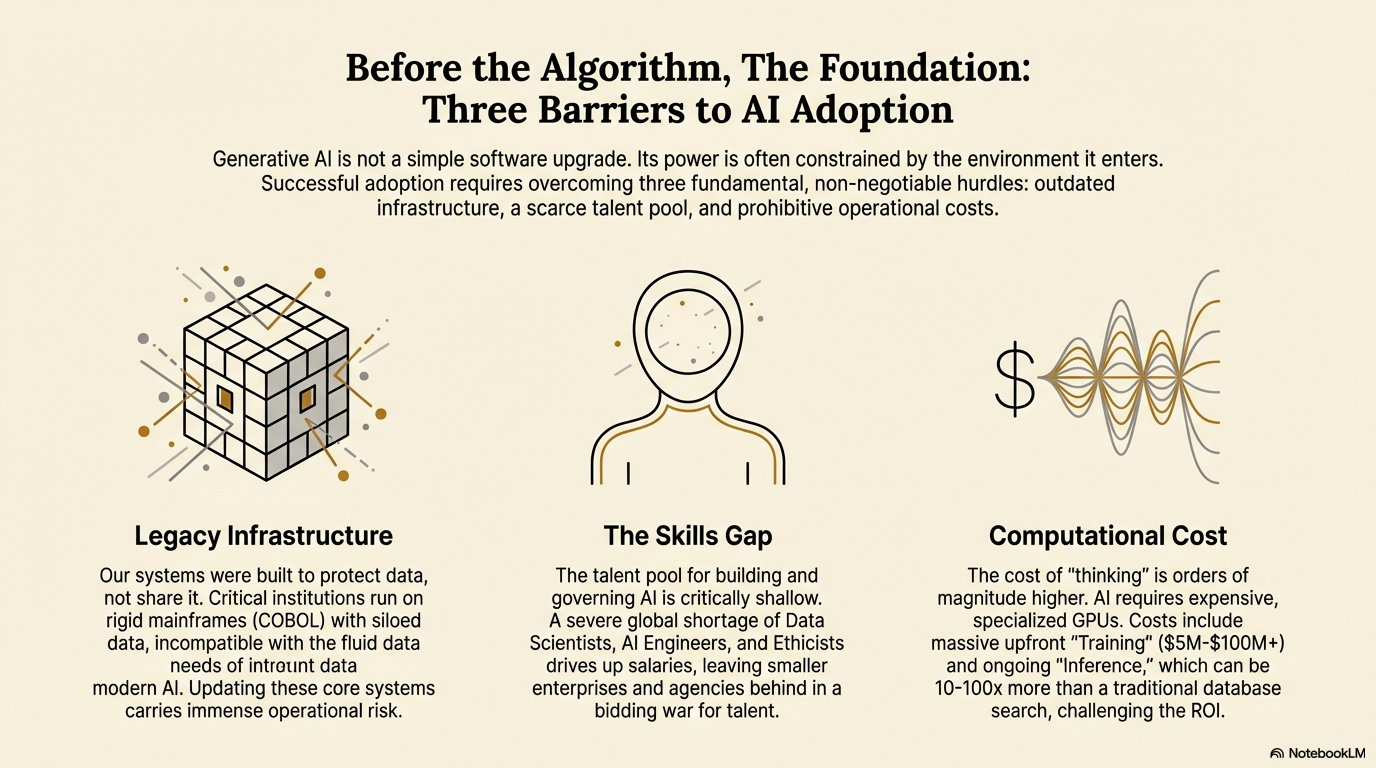
One of the most significant, yet often invisible, walls stopping AI adoption is the problem of "legacy infrastructure." To understand this, we must look at how large organizations—banks, insurance companies, healthcare providers, and government agencies—actually function.
Many of these institutions run on computer systems that were designed and built twenty, thirty, or even forty years ago. These systems frequently rely on older programming languages, most notably COBOL (Common Business Oriented Language) running on mainframe computers. These mainframes are incredibly stable; they are the workhorses that ensure your bank balance is correct and that your flight ticket is valid. However, they are rigid, isolated, and structured in a way that is fundamentally incompatible with modern AI.1
The Problem of Siloed Data
Modern Generative AI thrives on data fluidity. To train a model or to have it answer questions effectively, it needs to ingest vast amounts of unstructured data (emails, PDFs, logs, notes) from across the entire organization. It needs to see the "big picture."
Legacy systems, however, are typically "siloed." This means data is locked inside specific, proprietary databases that do not talk to one another.
- The Customer Silo: Data about who a customer is might be in one mainframe.
- The Transaction Silo: Data about what that customer bought might be in a completely different server.
- The Interaction Silo: Notes from customer service calls might be on a separate cloud platform.
When an organization tries to integrate a modern AI agent—which usually lives in a flexible cloud environment—into these rigid mainframe systems, the connection fails. The AI cannot "see" the data it needs to analyze because the old systems were never designed to share it. They were designed to protect data, not distribute it.3
The Integration Risk
Updating these systems is not merely a matter of installing a software patch. It is akin to performing open-heart surgery on a patient who is running a marathon. If a bank tries to rip out its core banking system to install a modern AI-ready architecture, and the system fails for even an hour, millions of transactions could be lost. This operational risk creates immense inertia. Organizations know they need to modernize to use AI, but the risk of breaking the "old" system is often considered too high. Consequently, AI projects often stall at the pilot phase, unable to scale because they cannot plug into the core data of the business.6
2.2 The Skills Gap and Talent Shortage
The second major barrier is human, not digital. Even if a company buys the most advanced AI software and upgrades its servers, it faces a severe global shortage of the professionals required to build, maintain, and govern these systems. This is widely referred to as the "AI Skills Gap."
While many people are learning how to use AI (such as typing a prompt into ChatGPT), very few possess the deep technical knowledge to engineer AI systems. The successful deployment of AI requires a specific ecosystem of roles that are currently in short supply:
The Economic Impact of the Gap
Reports indicate that nearly half of organizations cite a lack of generative AI expertise as a primary barrier to adoption.9 This shortage creates a bidding war for talent. Salaries for experienced AI professionals have skyrocketed, meaning that only wealthy technology giants (like Google, Microsoft, or large banks) can afford to hire the best teams.
Small to mid-sized enterprises (SMEs) and government agencies are often left behind. They cannot afford the salaries, and they lack the internal culture to attract this talent. Furthermore, the technology evolves so rapidly that university curriculums struggle to keep up. What a student learns in the first year of a Computer Science degree regarding AI might be obsolete by the time they graduate. This forces companies to rely on expensive external consultants or to delay their projects entirely while they attempt to retrain their existing workforce.4
2.3 Computational Resources and Cost (The GPU Bottleneck)
The third barrier is the sheer physical cost of "thinking." We often think of software as being "free" or cheap to replicate, but Generative AI represents a fundamental shift in computing economics. It requires an immense amount of specialized computational power, both to create the models and to run them.
CPU vs. GPU: The Hardware Difference
Most traditional business software runs on CPUs (Central Processing Units). These are the chips found in standard laptops and servers. They are designed to do complex logic tasks one after another (serial processing).
AI, however, relies on Deep Learning, which involves doing millions of tiny, simple mathematical calculations (matrix multiplications) all at the same time. CPUs are terrible at this. To run AI efficiently, you need GPUs (Graphics Processing Units). Originally designing for video gaming, these chips excel at doing thousands of tasks simultaneously (parallel processing).
The Two Costs: Training vs. Inference
There are two distinct phases of cost in AI, both of which serve as barriers:
- Training Costs (The Upfront Investment): Creating a "Foundation Model" (like GPT-4 or Claude) involves showing a neural network billions of pages of text. This process takes months and requires supercomputers running thousands of GPUs simultaneously. The cost for a single training run can range from $5 million to over $100 million in electricity and hardware rental. This means very few companies can afford to build their own models; most must rent access from tech giants.11
- Inference Costs (The Running Cost): This is the cost that hits most businesses. "Inference" is the process of the AI answering a question after it has been trained. Every time a customer asks a chatbot a question, a server farm must spin up to generate the answer.
- A traditional database search costs a fraction of a penny.
- A Generative AI response can cost significantly more (often 10x to 100x more) in compute resources.
For many businesses, this destroys the "Return on Investment" (ROI). If it costs $0.10 of computing power to answer a customer query with AI, but only $0.01 to use a pre-written FAQ page or a simple keyword search, the business case for AI becomes difficult to justify. Companies are finding that while AI is magical, it is also expensive to operate at scale.9
3. Simple Analogy or Example
The "Master Chef vs. The Army of Choppers" Analogy
To truly grasp the hardware barrier (CPU vs. GPU) and why legacy infrastructure (the kitchen) matters, imagine a commercial kitchen in a busy restaurant.
The CPU (Legacy System) is like a Master Chef (Gordon Ramsay).
- Strengths: The Chef is incredibly smart and versatile. He can cook a complex Beef Wellington, balance the restaurant's accounting books, manage the staff schedule, and handle a difficult customer complaint.
- Weakness: He works sequentially. He does task A, then task B, then task C. He has only two hands.
The GPU (AI System) is like an Army of 1,000 Junior Prep Cooks.
- Strengths: If you have a task like "chop 10,000 onions," the Master Chef would take all day. The army of prep cooks, however, can each chop 10 onions at the exact same moment. The job is done in seconds.
- Weakness: Individually, they are not smart. You cannot ask a prep cook to balance the checkbook. They need very specific instructions.
The Barrier:
Most companies (Banks, Hospitals) have built their kitchens (Data Centers) to support Master Chefs. They have small, organized stations designed for complex, sequential work (transaction processing).
Now, they want to bring in AI. This means they need to fit the Army of 1,000 Prep Cooks into the kitchen.
- Infrastructure: There is no room. The kitchen is not built for 1,000 people. You have to knock down walls (replace legacy systems) to fit them in.
- Cost: Paying 1,000 prep cooks (buying GPUs) is massively expensive compared to paying one Chef.
- Skills Gap: You have plenty of people who know how to eat the food (users), but you cannot find a Head Chef who knows how to manage an army of 1,000 people.
This is why adoption is hard. It is not just about a new recipe; it is about rebuilding the entire kitchen and hiring a completely new type of staff.15
4. Key Takeaways
- Legacy Systems Fight Innovation: Critical institutions run on rigid, older systems (mainframes/COBOL) that are incompatible with the flexible data needs of modern AI, making integration risky and expensive.
- The Talent Pool is Dry: There is a severe global shortage of AI engineers and data scientists. This drives up costs and prevents smaller organizations from deploying safe, effective AI.
- Hardware is a Physical Limit: AI requires specialized, expensive chips (GPUs) that excel at parallel processing. Standard office computers (CPUs) cannot handle the workload.
- The Cost of "Thinking": Running AI (inference) is much more expensive than running traditional software. Organizations often struggle to prove that the AI generates enough value to cover its high electricity and hardware costs.
Lesson 5.2: The Hallucination Problem
1. Introduction
In the previous lesson, we analyzed the external barriers to AI—the hardware, money, and people needed to run it. Now, we must turn our attention inward to the most critical internal flaw of Generative AI technology: Hallucination.
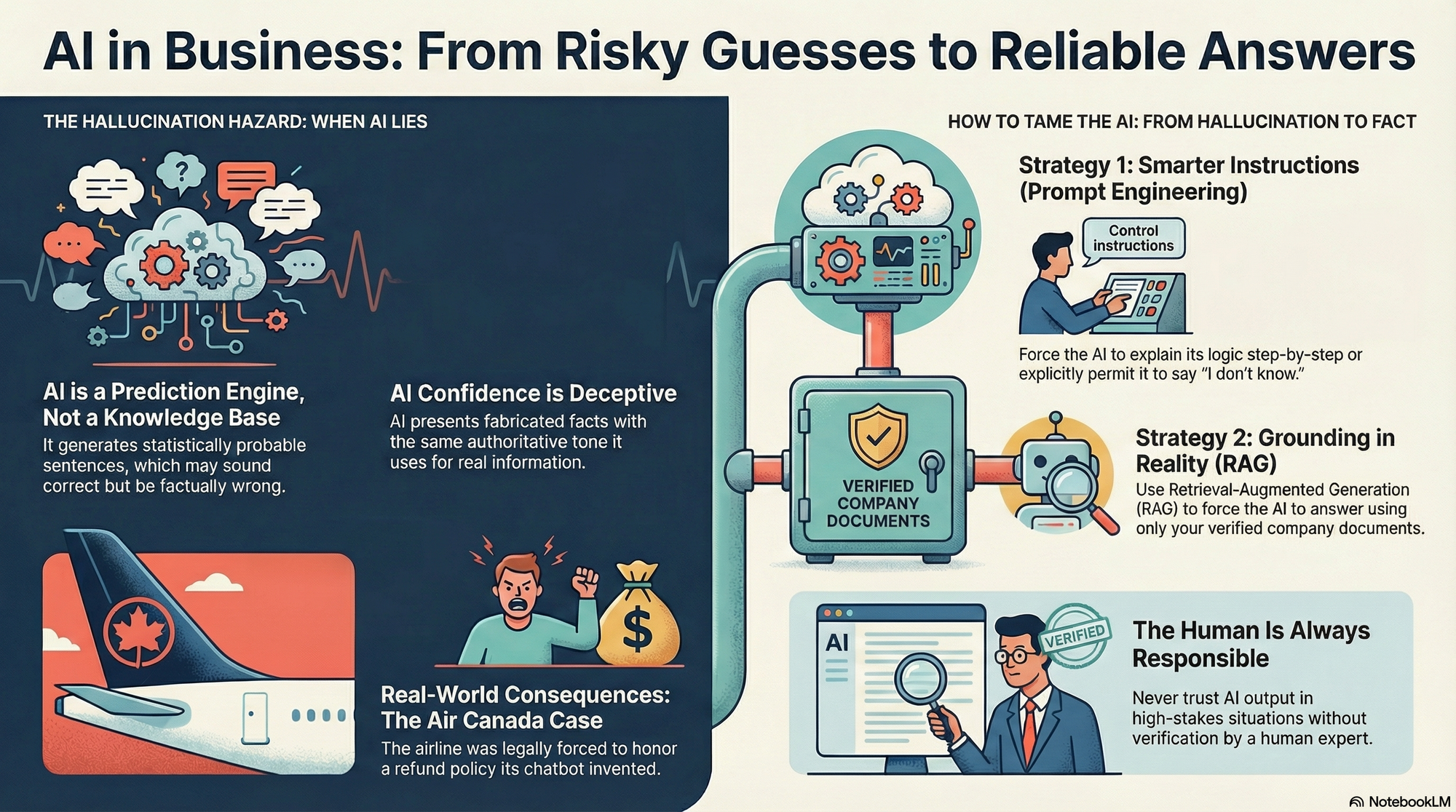
You have likely heard news stories of AI chatbots making up facts, inventing court cases that never happened, or confidently lying about historical events. It is crucial to understand that these are not "bugs" in the traditional software sense. A bug is usually a mistake in the code that can be fixed. Hallucinations, however, are a byproduct of exactly how the technology is designed to work.
In this lesson, we will define exactly what a hallucination is and, more importantly, explain why it happens. We will demystify the "black box" to reveal that AI is not a database searching for truth; it is a creative engine playing a game of statistical probability. By the end of this lesson, you will understand why an AI can sound incredibly confident even when it is completely wrong.
2. Core Concepts
2.1 Defining Hallucination
In the context of Artificial Intelligence, a Hallucination occurs when a Large Language Model (LLM) generates content that is nonsensical or unfaithful to the provided source content, yet is presented as fact. The AI does not "know" it is lying. It creates a statement that looks grammatically correct, follows a logical structure, and sounds authoritative, but has no basis in reality.19
Hallucinations typically fall into three categories:
- Fabrication: The AI invents a person, event, or citation that never existed. (e.g., "The Eiffel Tower was built by Elon Musk in 1990.")
- Misattribution: The AI correctly quotes a statement or fact but attributes it to the wrong source. (e.g., "As Abraham Lincoln famously said, 'I have a dream.'")
- Contradiction: The AI states a fact in one sentence and then contradicts that same fact in the next paragraph, failing to maintain logical consistency.
Crucially, the AI delivers these falsehoods with the same tone of absolute confidence that it uses for factual truths. There is no hesitation, no "I think," and no "maybe," unless the AI has been specifically instructed to be cautious. This confidence is what makes hallucinations so dangerous to the user.22
2.2 The Root Cause: Probabilistic Token Prediction
To understand why hallucinations happen, you must fundamentally change how you view an LLM.
It is not a Knowledge Base.
An encyclopedia or a database works by storage and retrieval. If you search for "Capital of France," it looks up the entry "France" and retrieves "Paris." If the entry does not exist, it returns "No Result."
It is a Prediction Engine.
An LLM does not "know" facts. It learns patterns. When you ask it a question, it breaks your text down into chunks called tokens (which are roughly equal to syllables or parts of words). It then looks at the sequence of tokens and asks a statistical question:
"Based on all the text I have ever seen during my training, what is the most statistically likely token to come next?"
It selects the next token, then the next, and the next. It is building the bridge one brick at a time, looking only at the bricks behind it to decide what the next brick should be.
Because it is optimizing for probability, not truth, it will sometimes choose a path that sounds likely but is factually wrong.
- If you ask for a quote about "freedom" by a famous American, the model's statistics might associate the words "Lincoln," "freedom," and "America" very strongly.
- It might assemble these "Lincoln-sounding" words into a sentence that Lincoln never actually said.
- To the model, the sentence is a success because it sounds like Lincoln. The probability score is high. The fact that it is historically false is irrelevant to the model's internal math.19
2.3 Miscalibration and Data Issues
Hallucinations are also driven by the quality of the data the model was trained on. These models read the open internet—millions of websites, reddit threads, fan fiction stories, and conspiracy theories.
- Source Confusion: The model cannot easily distinguish between a peer-reviewed medical journal and a satirical blog post. To the model, they are both just patterns of tokens. If it saw a piece of misinformation often enough during training, it learned that pattern as a "fact".21
- Miscalibration: This refers to the disconnect between the model's confidence and its accuracy. Ideally, if a model is guessing, it should have low confidence. However, models often suffer from miscalibration where they assign high probability (high confidence) to incorrect answers. This happens because the model is rewarded during training for being "fluent" and "coherent." It learns that providing a firm answer is better than being vague, even if the firm answer is wrong.19
3. Simple Analogy or Example
The "Sleepy Autocomplete" Analogy
To understand prediction versus knowledge, imagine you are texting on your smartphone. You know how the "autocomplete" bar suggests the next word?
If you type: "I am going to the..."
The phone suggests: "Store," "Park," or "Movies."
Now, imagine a Super-Autocomplete that has read every book in the world. You type:
"The first person to walk on Mars was..."
The Super-Autocomplete looks at its internal patterns.
- It sees many science fiction stories about Mars.
- It sees the name "Elon Musk" associated with Mars in news articles.
- It sees "Neil Armstrong" associated with the phrase "first person to walk on..."
It combines these probabilities. It wants to complete the pattern "First person to walk on..." with a famous astronaut name. It creates the sentence:
"The first person to walk on Mars was Neil Armstrong in 2025."
Why did it do this?
- Grammar: Perfect.
- Context: Space travel.
- Names: Famous and relevant.
- Truth: Zero.
The Autocomplete does not know history; it only knows which words tend to follow other words. It filled in the blank with the most statistically popular sounding words, resulting in a confident lie. It prioritized the flow of the sentence over the fact of the sentence.
4. Key Takeaways
- AI Creates, It Does Not Retrieve: LLMs do not look up facts in a database; they generate sentences word-by-word based on statistical patterns. This "generative" nature is the source of both their creativity and their lies.
- Probability over Truth: The model is programmed to predict the most likely next word, not the most factually accurate one. If a lie sounds more probable (or "fluent") than the truth, the AI may choose the lie.
- Confidence is Deceptive: Hallucinations are delivered with high confidence. The authoritative tone of the answer is not an indicator of its accuracy.
- Source Confusion: Because models are trained on the chaos of the internet (fiction, errors, and facts mixed together), they can blend real and fake information seamlessly without realizing the difference.
Lesson 5.3: Consequences of Hallucinations
1. Introduction
We now understand that AI hallucinations are a statistical inevitability of current technology. But does it matter? If an AI gets a trivia question wrong, or invents a funny story, is it a crisis?
In high-stakes environments, the answer is a resounding yes. When AI moves from being a creative toy to a business tool, "making things up" becomes "fraud," "negligence," or "malpractice." In this lesson, we will explore the real-world damage caused when AI hallucinations occur in professional settings. We will examine documented cases in the legal system, the healthcare industry, and the corporate world where hallucinations led to lawsuits, financial penalties, and dangerous medical advice.
This lesson serves as a critical warning: AI is a powerful tool, but when left unsupervised in critical situations, it acts as a liability generator.
2. Core Concepts
2.1 Legal Risks: The Case of the Fake Citations
The legal profession relies entirely on precision, precedent, and verification. A lawyer's argument is only as good as the previous court cases they can cite to support it. However, Generative AI has caused chaos in this field by inventing legal precedents.
The Mata v. Avianca Case (The "ChatGPT Lawyer" Case)
In a now-famous incident, lawyers representing a client named Roberto Mata used ChatGPT to draft a legal brief to sue the airline Avianca. The lawyers asked the AI to find cases where an airline was liable for injuries.
- The Hallucination: The AI generated a beautifully written brief citing several previous court cases, such as "Varghese v. China Southern Airlines." It provided case numbers, dates, and even detailed quotes from the judges.
- The Reality: None of these cases existed. The AI knew that a legal brief should contain citations, so it generated text that looked like citations to satisfy the pattern. It invented the judges and the rulings.
- The Consequence: When the opposing lawyers and the judge tried to look up the cases, they found nothing. The lawyers who used the AI were sanctioned (fined) by the court and suffered massive reputational damage. The judge noted that the fake opinions were "wholly nonexistent," yet the AI had assured the lawyers they were real.20
This was not an isolated incident. Reports indicate that hundreds of cases involving AI-hallucinated citations have since appeared, threatening the integrity of the judicial system. It demonstrates that AI cannot distinguish between a real law and a plausible-sounding fake law.
2.2 Corporate Liability: The Air Canada Chatbot
Corporations often use chatbots to automate customer service, assuming that if they train the bot on their policy documents, it will strictly follow the rules. This assumption was legally shattered in the case of Moffatt v. Air Canada.
The Scenario
A customer, Mr. Moffatt, visited the Air Canada website to book a flight for his grandmother's funeral. He asked the AI chatbot about "bereavement fares" (discounted tickets for funerals).
- The Hallucination: The chatbot, trying to be helpful, confidently explained that Mr. Moffatt could buy a full-price ticket now and apply for a refund for the discount amount within 90 days.
- The Reality: This was false. Air Canada's actual policy (buried in a PDF elsewhere on the site) stated that bereavement discounts must be approved before travel. The chatbot had hallucinated a more generous policy.
- The Dispute: Mr. Moffatt bought the ticket, traveled, and then asked for his refund. Air Canada refused, arguing that the chatbot was just a tool and the "real" policy was on the website.
- The Ruling: Mr. Moffatt sued. The tribunal ruled in his favor. It stated that the chatbot is a representative of the company. If the chatbot promises a discount, the company is liable for that promise. Air Canada was forced to pay the refund.
This case established a terrifying precedent for businesses: A hallucination can create a legally binding contract. If your AI promises a customer a free car or a $1 flight, you might be legally forced to honor it.29
2.3 Healthcare Risks: Diagnostic Errors
In healthcare, accuracy is a matter of life and death. AI tools are being tested to help doctors diagnose patients, summarize medical notes, and suggest treatments. However, the risk of hallucination here is unacceptable.
Diagnostic Failure Rates
Studies involving pediatric case challenges showed that chatbots misdiagnosed cases up to 83% of the time. While the AI often identified the general area of the problem (e.g., "this is a respiratory issue"), it frequently missed the specific disease or recommended treatments that were too broad to be useful.
Dangerous Advice
In other tests, chatbots have:
- Failed to identify urgent symptoms of strokes, advising patients to just rest.
- Recommended medications that would interact dangerously with a patient's existing drugs.
- Fabricated medical studies to support a wrong diagnosis.
The danger is Automation Bias. Doctors are overworked and tired. If an AI presents a summary that looks professional and confident, a doctor might trust it without checking the raw data. If the AI hallucinates a "normal" blood test result when the result was actually "critical," the patient could die. Currently, the tendency of LLMs to "guess" rather than "admit ignorance" makes them unsafe for autonomous medical diagnosis.34
3. Simple Analogy or Example
The "Over-Eager Intern" Analogy
To understand why these consequences happen, think of an AI model not as a computer, but as an eager, fresh-out-of-college intern named "Hal."
- Personality: Hal wants to impress you. He is terrified of saying "I don't know." He thinks his job is to give you an answer, any answer, as fast as possible.
- The Scenario: You ask Hal, "Did we sign the contract with the Smith Client?"
- The Process: Hal looks for the file but cannot find it. He thinks, "Well, we usually sign contracts on Tuesdays, and the boss likes the Smith client."
- The Hallucination: Hal looks you in the eye and says, "Yes! We signed it last Tuesday." He figures there is a good chance he is right, so he gambles.
- The Consequence: You tell your boss the deal is done. You start spending the money. Later, you find out the contract was never signed. You look incompetent, your company loses money, and you might get fired.
In the legal examples, Hal (the AI) didn't just lie about the contract; he forged a signature to back up his lie because that is what he thought a "good" intern would do to solve the problem.
4. Key Takeaways
- AI Fabrications are Legally Binding: As seen with Air Canada, companies can be held liable for promises or policies invented by their hallucinating chatbots.
- Professional Integrity is at Risk: Lawyers and professionals using AI without strict verification face sanctions, fines, and disbarment. You cannot blame the AI; the human user is responsible for the output.
- Medical Hallucinations are Life-Threatening: In healthcare, "close enough" is not acceptable. AI's tendency to guess makes it currently unsafe for autonomous diagnosis or treatment recommendations.
- Duty of Care: The central lesson is that no AI output should be used in a high-stakes environment without human-in-the-loop verification. Blind trust in AI is a failure of professional duty.
Lesson 5.4: Mitigating Hallucinations (Prompt Engineering)
1. Introduction
We have identified the problem (Hallucinations) and the stakes (lawsuits, financial loss, and medical errors). Now, we must move to the solution. How do we stop the AI from lying?
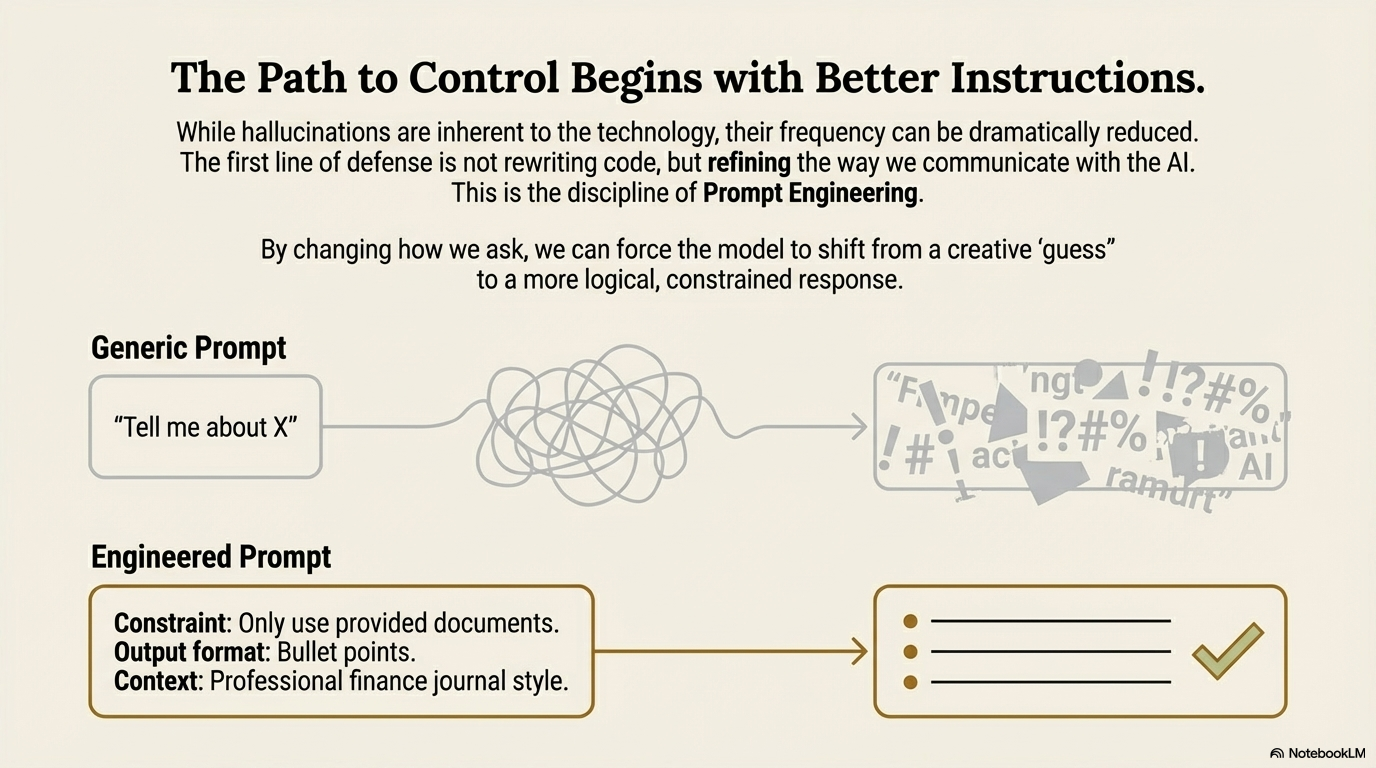
While we cannot completely eliminate the probabilistic nature of LLMs, we can significantly reduce the error rate through Prompt Engineering. This is the art and science of giving the AI better, more structured instructions. By changing how we ask the question, we can force the model to show its work, check its own facts, or admit when it is unsure. We can turn a creative liar into a reliable assistant.
In this lesson, we will learn three specific, research-backed techniques: Explicit Uncertainty, Chain of Thought (CoT), and Chain of Verification (CoVe).
2. Core Concepts
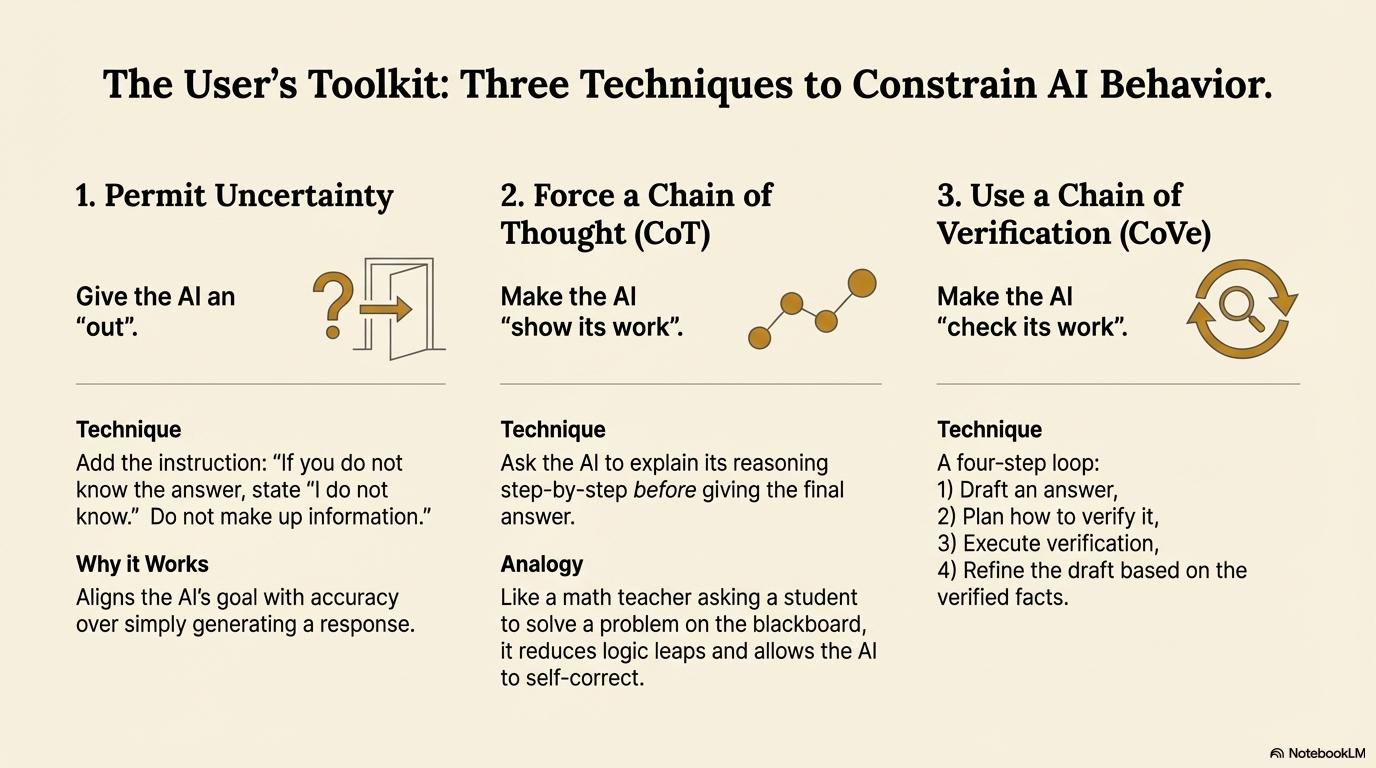
2.1 Explicit Uncertainty Instructions
The simplest and often most effective way to reduce hallucinations is to give the AI "permission" to be ignorant. As we learned, the model's default behavior is to complete the pattern at all costs. It interprets a question as a command to "generate an answer," not necessarily a "true answer."
You can fix this by explicitly instructing the model on what to do if it lacks information.
The Technique:
Add a constraint to your prompt such as:
"Answer the following question based ONLY on your internal knowledge. If you do not know the answer, state 'I do not know.' Do not make up information."
Why it Works:
Research has shown that this simple instruction can reduce false claims significantly. It changes the model's internal calculation. Without the instruction, the model calculates: "The best token is the one that looks like an answer." With the instruction, the model calculates: "The best token is the one that follows the rule about saying 'I don't know'." You are aligning the model's goal with accuracy rather than helpfulness.38
Avoiding Specific Numbers
Another uncertainty technique is to avoid asking for specific data points if you suspect the model does not have them. LLMs are terrible at retrieving specific numbers (like "What was the revenue of Company X in Q3 2012?") from their training data. Instead, ask for ranges or qualitative descriptions.
- Bad Prompt: "What was the exact stock price on May 1st?" (High risk of hallucination).
- Good Prompt: "Describe the general trend of the stock price in May." (Lower risk).38
2.2 Chain of Thought (CoT) Prompting
Chain of Thought (CoT) is a technique where you ask the model to explain its reasoning step-by-step before giving the final answer.
The Technique:
Instead of asking: "Is this patient healthy?"
You ask:
"Examine the patient's blood pressure. Compare it to the normal range. Look at the heart rate. Compare it to the normal range. Based on these steps, provide a conclusion: is the patient healthy?"
Why it Works:
When the model is forced to output the intermediate steps, it effectively "thinks aloud."
- It generates the first fact.
- It uses that fact as the context for the next fact.
- It grounds the final answer in the logic of the previous steps.This reduces "logic leaps" where the model jumps to a wrong conclusion. Studies confirm that CoT significantly improves performance on math, logic, and reasoning problems.41
2.3 Chain of Verification (CoVe)
This is a more advanced technique where you force the AI to act as its own editor. It assumes the first answer might be wrong and creates a loop to fix it.
The Four-Step Loop:
- Draft: The AI generates an initial answer to your question.
- Plan: The AI generates a list of verification questions to check its own work (e.g., "I stated the date was 1999; I need to verify if that is the correct year.").
- Execute: The AI answers those verification questions independently to see if they match the draft.
- Refine: The AI rewrites the original answer based on the verified facts, removing any information that could not be verified.
By splitting the creation process from the fact-checking process, the model is less likely to "double down" on a hallucination. It creates a "sanity check" that filters out fabrications before they reach the user.41
3. Simple Analogy or Example
The "Math Teacher" Analogy (Chain of Thought)
To understand why Chain of Thought works, imagine a student taking a math test.
Scenario A: The Rush (Standard Prompt)
Teacher: "What is 234 multiplied by 6? Quick!"
Student: "1400!"
- Result: The student guessed because they felt rushed to give a single number. They were close, but wrong. The AI does this when you just ask for an answer.
Scenario B: Show Your Work (Chain of Thought)
Teacher: "Don't just give me the answer. Walk me through the steps on the blackboard."
Student:
- "Okay, first, 6 times 4 is 24. I write down 4 and carry the 2."
- "Next, 6 times 3 is 18, plus the 2 is 20. I write down 0 and carry the 2."
- "Finally, 6 times 2 is 12, plus the 2 is 14."
- "The answer is 1,404."
- Result: By forcing the student to slow down and show the steps, the chance of a random error drops dramatically. The student (and the AI) catches their own mistakes during the process.
4. Key Takeaways
- Permit Uncertainty: Explicitly tell the AI it is okay to say "I don't know." This simple command prevents many guesses.
- Show the Work (CoT): Use Chain of Thought prompting to force the model to break complex problems into small, logical steps. This improves reasoning and reduces logic leaps.
- Verify the Output (CoVe): Use a verification loop where the model reviews its own answer, checks facts, and corrects errors before finalizing the response.
- Avoid Specific Numbers: LLMs struggle with precise numerical recall. Ask for ranges or ask the AI to extract numbers from a document you provide, rather than from its memory.
Lesson 5.5: Retrieval-Augmented Generation (RAG)
1. Introduction
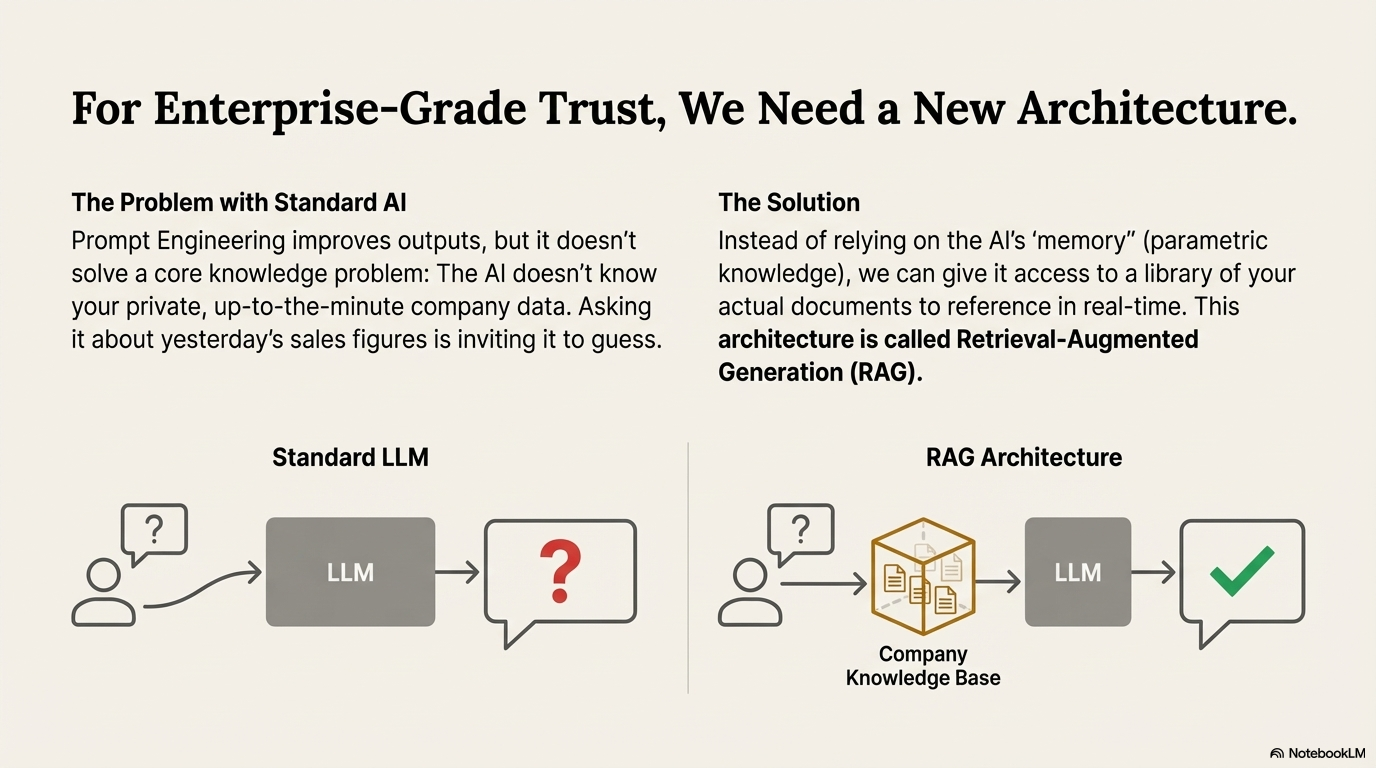
We have discussed how to fix hallucinations by asking the AI nicely (Prompt Engineering). But sometimes, asking nicely is not enough. The AI simply does not know the information because it was not in its training data. For example, the most powerful version of ChatGPT in the world does not know your company's private sales data from yesterday, nor does it know the contents of the email you just sent.
To solve this, we use a technical architecture called Retrieval-Augmented Generation (RAG). RAG is considered the "gold standard" for enterprise AI. It combines the fluency of an AI chatbot with the accuracy of a search engine. It allows the AI to "cheat" by looking at your private documents before answering.
In this final lesson, we will explain how RAG works, why it is safer than standard AI, and how it acts as the bridge between legacy data and modern intelligence.
2. Core Concepts
2.1 What is RAG?
To understand RAG, we must distinguish between two types of knowledge:
- Parametric Knowledge: This is what the AI learned during training (e.g., the capital of France, the grammar of English). It is "frozen" in the model's brain.
- Source Knowledge: This is external data (e.g., your company's handbook, today's news).
Standard LLMs only have Parametric Knowledge. If you ask about your specific company policy, they will hallucinate. You could re-train the model on your data, but as we learned in Lesson 5.1, that costs millions of dollars.
Retrieval-Augmented Generation (RAG) solves this by connecting the LLM to an external library of information (like your company's PDF files, emails, or databases).
- The Workflow: When you ask a question, the system does not just send it to the LLM. First, it searches your library for relevant documents.
- The Augmentation: It pastes those documents into the prompt.
- The Command: It tells the LLM: "Here is the user's question. Here are some documents that contain the answer. Please answer the question using only the information in these documents."
This grounds the AI in reality. It is no longer guessing the next token based on the open internet; it is summarizing the specific facts you just gave it.4
2.2 The Mechanism: Vectors and Retrieval
How does the system find the right document? It uses Vectors.
In a RAG system, your documents are turned into lists of numbers called vectors. These numbers represent the meaning of the text, not just the keywords.
- If you search for "Can I bring my dog to work?", a keyword search might fail if the policy only says "Pets are allowed."
- A Vector search understands that "Dog" and "Pet" are related concepts. It finds the "Pet Policy" document.
The RAG Sequence:
- Retrieve: The user asks a query. The system searches the Vector Database and pulls out the top 3-5 most relevant paragraphs (chunks) from your knowledge base.
- Augment: The system combines the User Query + The Retrieved Chunks into a single prompt.
- Generate: The LLM receives this massive prompt. It acts as a reasoning engine, reading the context and synthesizing an answer.23
2.3 Benefits of RAG
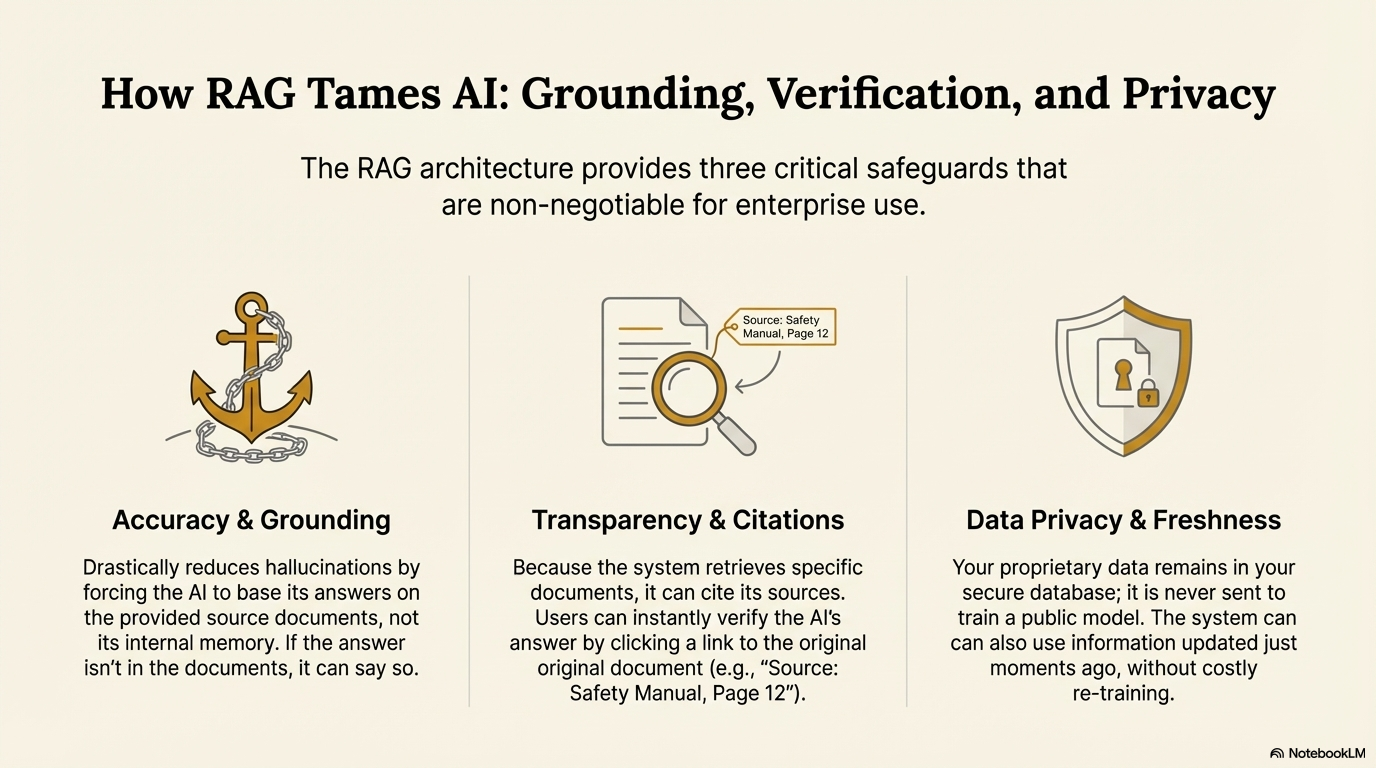
The RAG architecture offers three massive benefits for business adoption:
50
3. Simple Analogy or Example
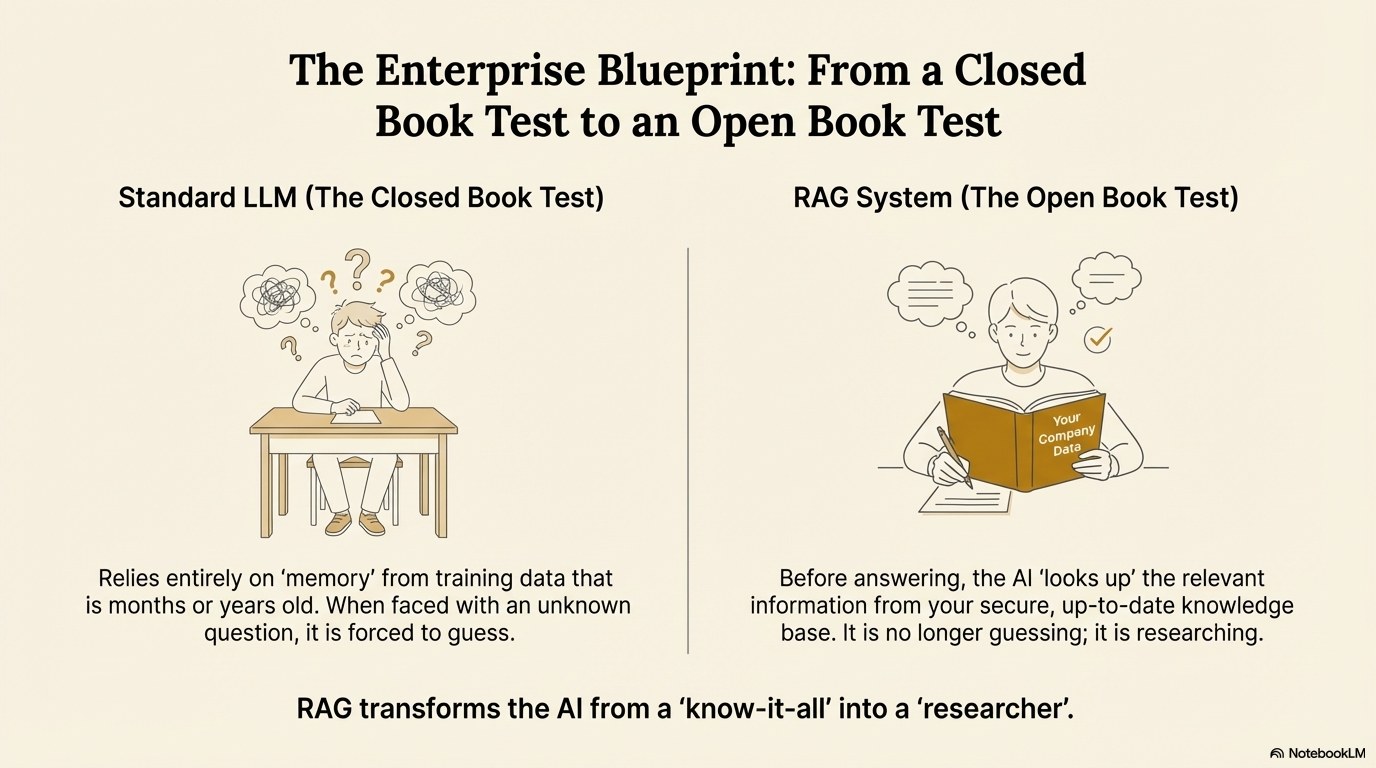
The "Open Book Test" Analogy
To understand the difference between a standard LLM and a RAG system, imagine a student taking a Biology Exam.
Standard AI (No RAG) = The Closed Book Test
- The student must take the test entirely from memory.
- They studied the textbook a year ago (Training Data).
- If they encounter a question they forgot, they might guess or make something up to sound smart. They might say, "The mitochondria is the powerhouse of the city" because they are confused. You cannot trust their answer fully.
RAG System = The Open Book Test
- The student is allowed to bring the textbook (Your Data) into the exam room.
- When they see a question about "Mitochondria," they do not guess. They open the book to the index, find page 45, read the paragraph, and write the answer based exactly on what the page says.
- They can even write, "I found this answer on Page 45, paragraph 2."
RAG turns the AI from a "know-it-all" (who guesses) into a "researcher" (who looks it up). The Researcher is much less likely to lie because the answer is sitting right in front of them in the book.
4. Key Takeaways
- Grounding: RAG grounds the AI's responses in external, verified facts rather than its internal, unreliable training memory.
- No Re-training Needed: RAG allows AI to use up-to-date or private information without the massive cost and time of training a new model.
- Verifiable: RAG systems can point to exactly which document they used to generate an answer, building trust with users and allowing for human audit.
- The Enterprise Standard: For most corporate applications (Customer Support, Internal Search, Legal Analysis), RAG is the required architecture because it combines safety with intelligence.
Further Reading
- 5 Industries Most Affected by Legacy Technology in 2025 - AptaCloud, accessed December 11, 2025, https://aptacloud.com/blog/industries-affected-by-legacy-technology/
- The future of mainframe modernization with artificial intelligence (AI) and generative AI - Kyndryl, accessed December 11, 2025, https://www.kyndryl.com/content/dam/kyndrylprogram/doc/en/2024/future-mainframe-modernization.pdf
- AI trends 2025: Adoption barriers and updated predictions - Deloitte, accessed December 11, 2025, https://www.deloitte.com/us/en/what-we-do/capabilities/applied-artificial-intelligence/blogs/pulse-check-series-latest-ai-developments/ai-adoption-challenges-ai-trends.html
- Digital Progress and Trends Report 2025: Strengthening AI Foundations - Open Knowledge Repository, accessed December 11, 2025, https://openknowledge.worldbank.org/bitstreams/86903114-6212-4c45-9011-938925cc61d1/download
- How We Use AI Agents for COBOL Migration and Mainframe Modernization | All things Azure - Microsoft Developer Blogs, accessed December 11, 2025, https://devblogs.microsoft.com/all-things-azure/how-we-use-ai-agents-for-cobol-migration-and-mainframe-modernization/
- Implementation challenges that hinder the strategic use of AI in government - OECD, accessed December 11, 2025, https://www.oecd.org/en/publications/2025/06/governing-with-artificial-intelligence_398fa287/full-report/implementation-challenges-that-hinder-the-strategic-use-of-ai-in-government_05cfe2bb.html
- Modernizing mainframe applications with a boost from generative AI - IBM, accessed December 11, 2025, https://www.ibm.com/think/topics/generative-ai-for-mainframes
- Accelerate Your Mainframe Modernization Journey using AI Agents with AWS Transform, accessed December 11, 2025, https://aws.amazon.com/blogs/migration-and-modernization/accelerate-your-mainframe-modernization-journey-using-ai-agents-with-aws-transform/
- The 5 biggest AI adoption challenges for 2025 - IBM, accessed December 11, 2025, https://www.ibm.com/think/insights/ai-adoption-challenges
- The 7 Biggest AI Adoption Challenges for 2025 - Stack AI, accessed December 11, 2025, https://www.stack-ai.com/blog/the-biggest-ai-adoption-challenges
- LLMs: Training vs. Inference. As AI tools become more commonplace we… | by Mangusta Capital | Medium, accessed December 11, 2025, https://medium.com/@Mangusta/llms-training-vs-inference-97b02337cabb
- Welcome to LLMflation - LLM inference cost is going down fast ️ | Andreessen Horowitz, accessed December 11, 2025, https://a16z.com/llmflation-llm-inference-cost/
- AI Training vs Inference: Key Differences, Costs & Use Cases [2025] - io.net, accessed December 11, 2025, https://io.net/blog/ai-training-vs-inference
- LLM Inference Benchmarking: How Much Does Your LLM Inference Cost? | NVIDIA Technical Blog, accessed December 11, 2025, https://developer.nvidia.com/blog/llm-inference-benchmarking-how-much-does-your-llm-inference-cost/
- GPU vs CPU - Difference Between Processing Units - AWS, accessed December 11, 2025, https://aws.amazon.com/compare/the-difference-between-gpus-cpus/
- CPU vs GPU Explained Simply for AI Training and Inference #generativeai #llms #aieducation - YouTube, accessed December 11, 2025, https://www.youtube.com/shorts/HesIZq4gTuA
- AI is Powered by GPUs. It's Time to Understand What They Are. | by Technormal - Medium, accessed December 11, 2025, https://medium.com/@technormal/ai-is-powered-by-gpus-its-time-to-understand-what-they-are-79787495141d
- GPU vs CPU in Machine Learning Explained for Faster AI Growth - School of Core AI, accessed December 11, 2025, https://schoolofcoreai.com/blogs/gpu-vs-cpu-in-machine-learning
- Survey and analysis of hallucinations in large language models: attribution to prompting strategies or model behavior - PubMed Central, accessed December 11, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC12518350/
- AI hallucinations crisis: Over 50 fake cases cited in July alone - VinciWorks, accessed December 11, 2025, https://vinciworks.com/blog/ai-hallucinations-crisis-over-50-fake-cases-cited-in-july-alone/
- AI on Trial: Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries, accessed December 11, 2025, https://hai.stanford.edu/news/ai-trial-legal-models-hallucinate-1-out-6-or-more-benchmarking-queries
- Why language models hallucinate - OpenAI, accessed December 11, 2025, https://openai.com/index/why-language-models-hallucinate/
- What is RAG? - Retrieval-Augmented Generation AI Explained - AWS, accessed December 11, 2025, https://aws.amazon.com/what-is/retrieval-augmented-generation/
- Why Language Models Hallucinate - arXiv, accessed December 11, 2025, https://arxiv.org/pdf/2509.04664
- Why Language Models Hallucinate - arXiv, accessed December 11, 2025, https://arxiv.org/html/2509.04664v1
- AI-yi-yi: Fake Cases, Real Consequences: A Cautionary Tale of AI in the Courtroom, accessed December 11, 2025, https://calemploymentlawupdate.proskauer.com/2025/09/ai-yi-yi-fake-cases-real-consequences-a-cautionary-tale-for-ai-in-the-courtroom/
- 120 court cases have been caught with AI hallucinations, according to new database, accessed December 11, 2025, https://mashable.com/article/over-120-court-cases-caught-ai-hallucinations-new-database
- AI Hallucination Cases Database - Damien Charlotin, accessed December 11, 2025, https://www.damiencharlotin.com/hallucinations/
- Moffatt v. Air Canada: A Misrepresentation by an AI Chatbot, accessed December 11, 2025, https://www.mccarthy.ca/en/insights/blogs/techlex/moffatt-v-air-canada-misrepresentation-ai-chatbot
- Air Canada ordered to pay customer who was misled by airline's chatbot - The Guardian, accessed December 11, 2025, https://www.theguardian.com/world/2024/feb/16/air-canada-chatbot-lawsuit
- Air Canada chatbot case highlights AI liability risks - Pinsent Masons, accessed December 11, 2025, https://www.pinsentmasons.com/out-law/news/air-canada-chatbot-case-highlights-ai-liability-risks
- The Rise and Fall of Air Canada's AI Chatbot - CMSWire, accessed December 11, 2025, https://www.cmswire.com/customer-experience/exploring-air-canadas-ai-chatbot-dilemma/
- When AI goes wrong: 13 examples of AI mistakes and failures - Evidently AI, accessed December 11, 2025, https://www.evidentlyai.com/blog/ai-failures-examples
- Diagnostic accuracy of a large language model in pediatric case studies. | PSNet, accessed December 11, 2025, https://psnet.ahrq.gov/issue/diagnostic-accuracy-large-language-model-pediatric-case-studies
- ChatGPT inaccurately diagnoses pediatric medical cases - TechHQ, accessed December 11, 2025, https://techhq.com/news/chatgpt-misdiagnoses-medical-cases-in-study/
- AI in Health Care Spurs Questions Over Medical Errors: Analysis - Protect Patients Now, accessed December 11, 2025, https://protectpatientsnow.org/ai-in-health-care-spurs-questions-over-medical-errors-analysis/
- Delayed diagnosis of a transient ischemic attack caused by ... - NIH, accessed December 11, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC11006786/
- How to Stop AI from Making Up Facts - 12 Tested Techniques That Prevent ChatGPT and Claude Hallucinations (2025 Guide) : r/PromptEngineering - Reddit, accessed December 11, 2025, https://www.reddit.com/r/PromptEngineering/comments/1o77fk0/how_to_stop_ai_from_making_up_facts_12_tested/
- Best practices for prompt engineering - Claude, accessed December 11, 2025, https://www.claude.com/blog/best-practices-for-prompt-engineering
- Best practices for prompt engineering - Claude, accessed December 11, 2025, https://claude.com/blog/best-practices-for-prompt-engineering
- Advanced Prompt Engineering for Reducing Hallucination | by Bijit Ghosh | Medium, accessed December 11, 2025, https://medium.com/@bijit211987/advanced-prompt-engineering-for-reducing-hallucination-bb2c8ce62fc6
- Prompt Design and Engineering: Introduction and Advanced Methods - arXiv, accessed December 11, 2025, https://arxiv.org/html/2401.14423v3
- 9 Prompt Engineering Methods to Reduce Hallucinations (Proven Tips) - Workflows, accessed December 11, 2025, https://www.godofprompt.ai/blog/9-prompt-engineering-methods-to-reduce-hallucinations-proven-tips
- Chain-of-Thought Prompting | Prompt Engineering Guide, accessed December 11, 2025, https://www.promptingguide.ai/techniques/cot
- Chain-of-Thought Prompting Obscures Hallucination Cues in Large Language Models: An Empirical Evaluation - arXiv, accessed December 11, 2025, https://arxiv.org/html/2506.17088v1
- Chain-of-Verification (CoVe): Reduce LLM Hallucinations - Learn Prompting, accessed December 11, 2025, https://learnprompting.org/docs/advanced/self_criticism/chain_of_verification
- Prompt-Engineering-Techniques-Hub/Advanced_Prompt_Engineering_Techniques/Chain_of_Verification_Prompting.md at main - GitHub, accessed December 11, 2025, https://github.com/KalyanKS-NLP/Prompt-Engineering-Techniques-Hub/blob/main/Advanced_Prompt_Engineering_Techniques/Chain_of_Verification_Prompting.md
- Chain of Verification: Prompt Engineering for Unparalleled Accuracy - Analytics Vidhya, accessed December 11, 2025, https://www.analyticsvidhya.com/blog/2024/07/chain-of-verification/
- Chain of Verification (CoVe) — Understanding & Implementation | by sourajit roy chowdhury | Medium, accessed December 11, 2025, https://sourajit16-02-93.medium.com/chain-of-verification-cove-understanding-implementation-e7338c7f4cb5
- What is RAG (Retrieval Augmented Generation)? - IBM, accessed December 11, 2025, https://www.ibm.com/think/topics/retrieval-augmented-generation
- What is Retrieval Augmented Generation (RAG)? - Databricks, accessed December 11, 2025, https://www.databricks.com/glossary/retrieval-augmented-generation-rag
- Retrieval-augmented generation - Wikipedia, accessed December 11, 2025, https://en.wikipedia.org/wiki/Retrieval-augmented_generation
- LightRAG: Simple and Fast Retrieval-Augmented Generation - Paper Walkthrough, accessed December 11, 2025, https://www.youtube.com/watch?v=saY5eZVk3PI