
The Generative AI Revolution and Operational Lifecycle
1. Introduction: The Paradigm Shift in Artificial Intelligence
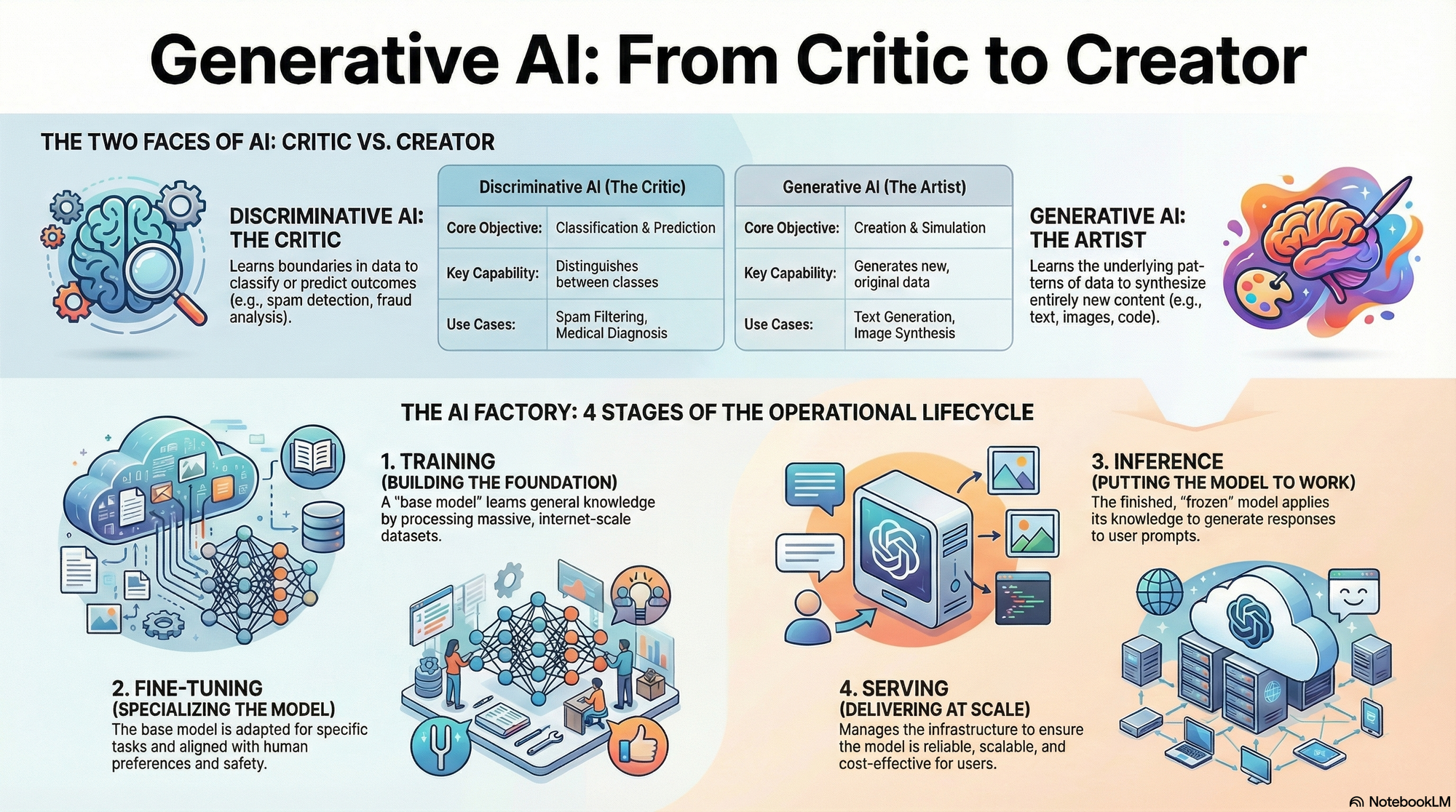
The history of artificial intelligence (AI) has been dominated by a single, prevailing paradigm: analysis. For decades, the most sophisticated systems were designed to dissect, categorize, and discriminate. These systems, known as discriminative models, functioned as the ultimate critics of the digital age. They could identify a fraudulent transaction among millions of legitimate ones, classify a tumor in a medical image with superhuman precision, or predict the likelihood of a customer churning. However, despite their analytical prowess, these models possessed a fundamental limitation: they could not create. They could analyze a symphony, but they could not compose one; they could critique a novel, but they could not write it.
The emergence of Generative AI (GenAI) represents a tectonic shift in this technological landscape. It marks the transition from curation to creation. Unlike their discriminative predecessors, generative models are designed to synthesize entirely new data instances—text, images, code, and audio—that are statistically indistinguishable from human-generated content.1 This capability is not merely an incremental improvement but a fundamental reimagining of what machine intelligence can achieve. It is powered by the convergence of massive datasets, unprecedented computational scale, and a novel neural architecture known as the Transformer, which has given rise to Large Language Models (LLMs).3
This report provides an exhaustive technical analysis of this revolution. It explores the theoretical divergence between generative and discriminative modeling, dissects the probabilistic engines of LLMs, demystifies the self-attention mechanisms that allow machines to understand context, and maps the rigorous operational lifecycle required to deploy these systems at scale. By synthesizing architectural theory with operational pragmatism, this document serves as a foundational guide to the mechanisms powering the modern AI ecosystem.
Slides






Explainer Video
2. Theoretical Foundations: Generative vs. Discriminative Models
To understand the generative revolution, one must first delineate the boundary between the two primary families of statistical modeling: Discriminative and Generative models. While both approaches leverage probability theory and optimization to learn from data, their objectives, mathematical formulations, and resulting capabilities are diametrically opposed.
2.1 The Discriminative Approach: The Critic
Discriminative models have historically served as the backbone of applied machine learning. Their primary function is classification or regression—mapping input variables ($X$) to a target variable ($Y$). In the context of a visual system, $X$ might be the pixel values of an image, and $Y$ might be the label "Cat" or "Dog".5
2.1.1 Mathematical Formulation: Conditional Probability
Mathematically, discriminative models attempt to learn the conditional probability distribution $P(Y|X)$ directly.6 This formulation reads as "the probability of label $Y$ given the input data $X$."
$$P(Y|X)$$
In this framework, the model is not required to understand the complex distribution of the input data itself ($P(X)$). It focuses solely on finding the decision boundary—the mathematical line or hyperplane—that separates classes. For example, in a Support Vector Machine (SVM) or a Logistic Regression model, the algorithm seeks a function that maximizes the separation between data points of different classes.8
2.1.2 The "Critic" Analogy
A robust analogy for the discriminative model is that of an art critic.1 The critic does not need to possess the skill to mix paints or apply brushstrokes (i.e., they do not need to understand the underlying distribution of the data). Their expertise lies solely in observing a finished work and assigning it to a category—Impressionist vs. Surrealist, or Authentic vs. Forgery. If you ask a discriminative model to "draw a dog," it fails; it has never learned what a dog is in a holistic sense, only what specific features distinguish a dog from a cat.5
Discriminative models are often referred to as "boundary learners".6 They learn the hard or soft boundaries between classes. This makes them highly efficient for tasks where the input space is well-defined and the objective is strictly categorization.
- Logistic Regression: Often considered the linear regression of classification, used to differentiate between two or more classes.8
- Support Vector Machines (SVMs): Powerful algorithms used for both classification and regression.8
- Decision Trees: Graphical models that map decisions to probable outcomes.8
2.1.3 Applications and Limitations
Discriminative models excel in high-stakes decision-making environments where the goal is accuracy in categorization.
- Fraud Detection: Classifying a transaction as "Fraud" or "Legitimate" based on transaction metadata. The model discriminates between safe and unsafe patterns.9
- Spam Filtering: Determining if an email is "Spam" or "Ham" based on keywords and sender reputation.10
- Medical Diagnosis: Identifying the presence of a specific pathology in an MRI scan. The model discriminates between healthy and unhealthy tissue.10
However, the limitation of this approach is its dependence on pre-existing data boundaries. A discriminative model cannot synthesize new data points to augment a small dataset, nor can it hallucinate new scenarios for simulation.10 It is purely reactive to the input provided.
2.2 The Generative Approach: The Creator
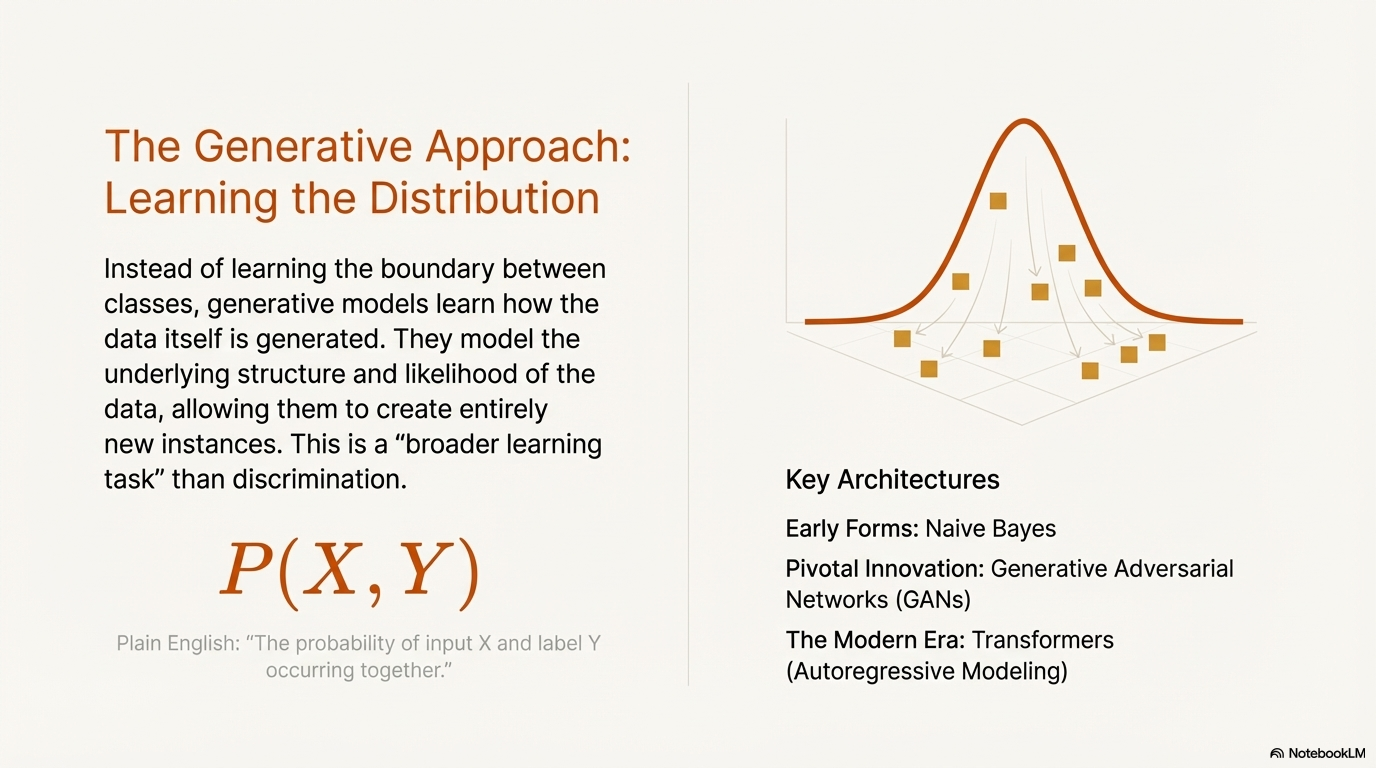
Generative models represent a more complex and computationally demanding approach. Instead of focusing on the boundary between classes, generative models focus on the data itself. Their goal is to model how the data is generated in the real world.
2.2.1 Mathematical Formulation: Joint Probability
Generative models aim to learn the joint probability distribution $P(X, Y)$ (in supervised settings) or simply $P(X)$ (in unsupervised settings).5 By understanding the joint probability, these models capture the underlying structure and likelihood of the data itself.
$$P(X, Y) = P(X|Y)P(Y)$$
Because they model $P(X)$, they can calculate the likelihood of any given data point appearing in the universe of the dataset. More importantly, they can sample from this distribution to create entirely new data instances ($\hat{X}$) that are statistically similar to the training data but not identical to it.11
Using Bayes' rule, a generative model can technically perform classification by deriving $P(Y|X)$ from $P(X,Y)$, but this is often computationally more expensive than the direct discriminative approach.7
2.2.2 The "Artist" Analogy
If the discriminative model is the critic, the generative model is the artist.1 To paint a portrait, an artist must understand the structure of the face, the interaction of light and shadow, and the texture of skin. They are not merely comparing the face to a rock; they are reconstructing the face from an internal understanding of "faceness." A generative model trained on images of horses learns the geometry, texture, and color distribution of horses, allowing it to sketch a horse that has never existed in reality.5
This analogy extends to the complexity of the task. It is generally easier to critique a painting than to paint one. Similarly, generative modeling is a "broader learning task" than discriminative modeling because the model must learn every feature of the input space, not just the features necessary for classification.5
2.2.3 Evolution of Generative Architectures
The field of generative AI has evolved through several key architectures, each increasing in fidelity and capability.
- Naive Bayes: One of the simplest generative models. It models $P(c)$ and $P(d|c)$ (where $c$ is class and $d$ is feature vector). By assuming independence between features, it simplifies the calculation of the joint probability $P(c,d)$.6
- Generative Adversarial Networks (GANs): A pivotal innovation involving two neural networks competing against each other.
- The Generator: Creates fake data points.
- The Discriminator: Tries to distinguish between real data and the fake data created by the generator.
- This adversarial dynamic forces the generator to produce highly realistic outputs to "fool" the discriminator.5
- Transformers (The Modern Era): Large Language Models utilize a specific type of generative modeling called autoregressive modeling, where the model predicts the next element in a sequence based on the probability of previous elements.12
2.3 Comparative Summary
The following table summarizes the distinctions between these two fundamental approaches to artificial intelligence.
5
3. Large Language Models (LLMs): The Engines of Revolution
The current explosion in Artificial Intelligence is primarily driven by a specific class of generative models known as Large Language Models (LLMs). These systems utilize deep learning techniques to process and generate human language with unprecedented fluency and reasoning capabilities. They are the core of the generative AI revolution.3
3.1 The Statistical Nature of Language
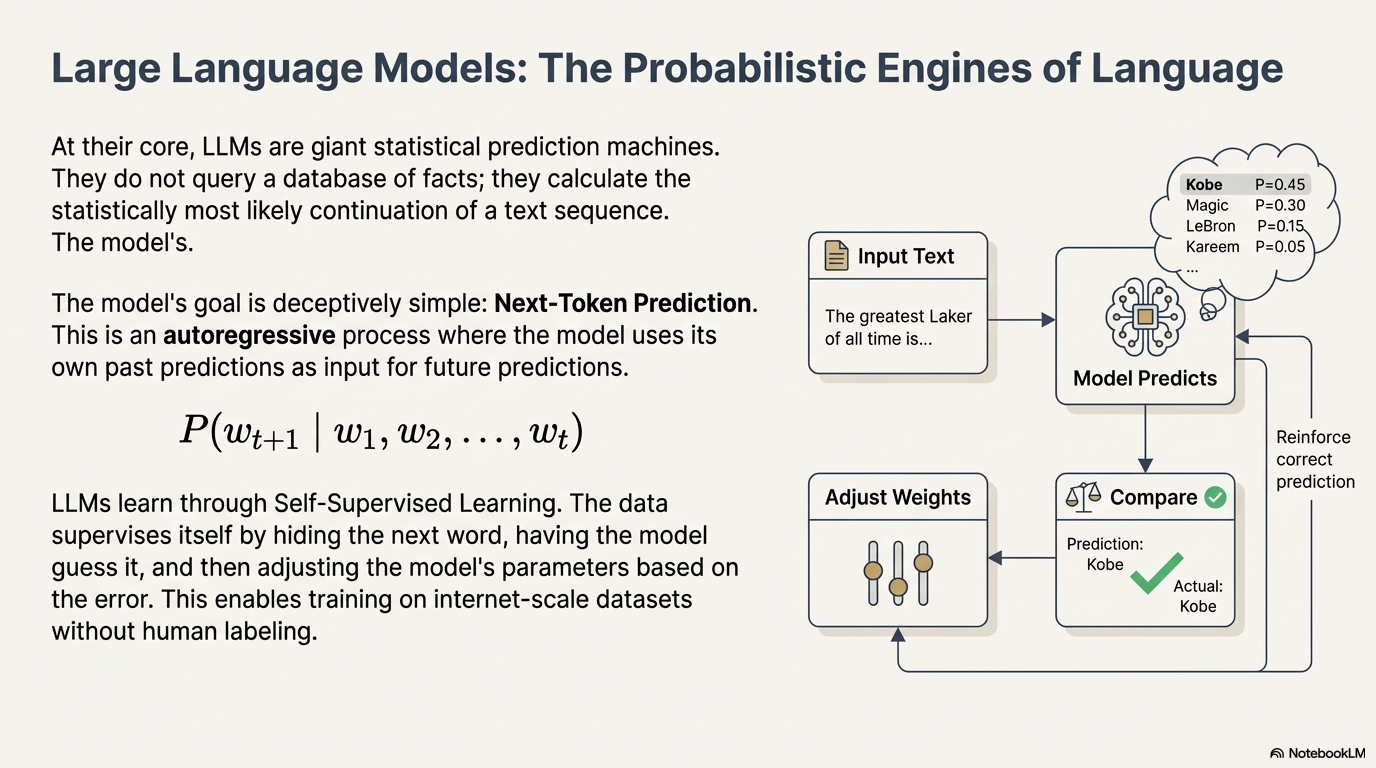
At their core, LLMs are probabilistic engines. They function as giant statistical prediction machines designed to determine the most likely continuation of a text sequence.3 Unlike symbolic AI systems of the past, which relied on hard-coded rules of grammar and logic, LLMs learn these rules implicitly by observing patterns in vast datasets.
When an LLM answers a question, it is not querying a structured database of verified facts. It is calculating: "Given the sequence of words in the user's question, what sequence of words is statistically most likely to follow?" This distinction is crucial for understanding both the power and the limitations (such as hallucinations) of these models.3
3.2 The Next-Token Prediction Objective
The training objective of an LLM is deceptively simple: Next-Token Prediction (often called Causal Language Modeling). This is an autoregressive process, meaning the model uses its own past predictions as input for future predictions.13
Given a sequence of words $w_1, w_2,..., w_t$, the model attempts to maximize the likelihood of the correct next word $w_{t+1}$:
$$P(w_{t+1} | w_1, w_2,..., w_t)$$
3.2.1 The "Autocomplete" Misconception
It is common to dismiss LLMs as merely "fancy autocomplete".13 While technically accurate in terms of mechanism, this reductionism ignores the complexity required to predict the next token in a sophisticated context.
Consider the sentence:
"The surgeon could not operate on the patient because he was his son."
Question: Who is the surgeon?
Answer: The patient's father.
To accurately predict the tokens "The patient's father," the model cannot simply rely on surface-level grammar or frequency statistics. It must resolve the ambiguity of the pronoun "he," understand the kinship relationship implied by "son," and apply the real-world constraint that a father is a male parent (in this specific context).
As the model scales, the task of "predicting the next word" forces the model to internalize the logic, causality, and sociology of the world described in the text. This phenomenon supports the hypothesis that "Compression is Intelligence"; to compress the data of the world into a predictive model, the system must learn the underlying rules that govern that data.3
3.2.2 Self-Supervised Learning
LLMs are trained via self-supervised learning. In traditional machine learning, humans must laboriously label data (e.g., "This is a cat," "This is a dog"). In LLM training, the data supervises itself.
- Input: "The greatest Laker of all time is"
- Target: "Kobe"The model hides the future word, guesses it, compares its guess to the actual word, and adjusts its parameters accordingly. This allows LLMs to be trained on the internet-scale datasets (trillions of words) without the need for human annotation.13
3.3 Tokenization: The Atomic Units of LLMs
LLMs do not read "words" in the linguistic sense; they process "tokens." Tokenization is the process of breaking text down into smaller, numerical units.4
- Words vs. Sub-words: While common words like "apple" might be single tokens, complex or rare words are broken into sub-word units. For example, "generative" might be tokenized as "gen", "er", "ative".
- Efficiency: This approach allows the model to handle a vast vocabulary with a finite set of atomic units (typically 32,000 to 100,000 unique tokens).
- Numerical Embeddings: Each token is converted into a high-dimensional vector called an embedding. These vectors place tokens in a multi-dimensional geometric space where semantically similar words are located closer together. For instance, the mathematical distance between the vector for "King" and "Queen" would be similar to the distance between "Man" and "Woman".4
3.4 Emergent Behaviors and Scaling Laws
The "Large" in Large Language Models refers to two dimensions:
- Parameter Count: The number of adjustable weights in the neural network (ranging from 7 billion to over 1 trillion).
- Data Volume: The size of the training corpus.
Research into scaling laws indicates that as the number of parameters and the volume of data increase, the model's loss (error rate) decreases predictably. However, beyond certain thresholds, models exhibit emergent behaviors—capabilities that were not explicitly trained for.
- A small model might learn grammar.
- A medium model might learn to summarize.
- A massive model might suddenly demonstrate the ability to translate between languages, write functional Python code, or perform multi-step logical deduction, despite never being explicitly taught these specific tasks. These capabilities emerge as a byproduct of learning to predict the next token over massive and diverse datasets.3
3.5 Future Directions: Beyond Next Token
While next-token prediction is the standard, research is exploring auxiliary objectives to improve performance.
- Multi-Token Prediction (MTP): Predicting several future tokens at once to improve efficiency and foresight.16
- Token Order Prediction (TOP): A softer objective that helps the model learn the relative order of upcoming tokens, enhancing its understanding of structure.16
4. The Role of the Transformer Architecture
If LLMs are the engine of the generative revolution, the Transformer architecture is the blueprint that makes the engine possible. Introduced by Google researchers in the seminal 2017 paper "Attention Is All You Need", the Transformer displaced Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks as the state-of-the-art for natural language processing.4
4.1 The Pre-Transformer Era: The Bottleneck of Recurrence
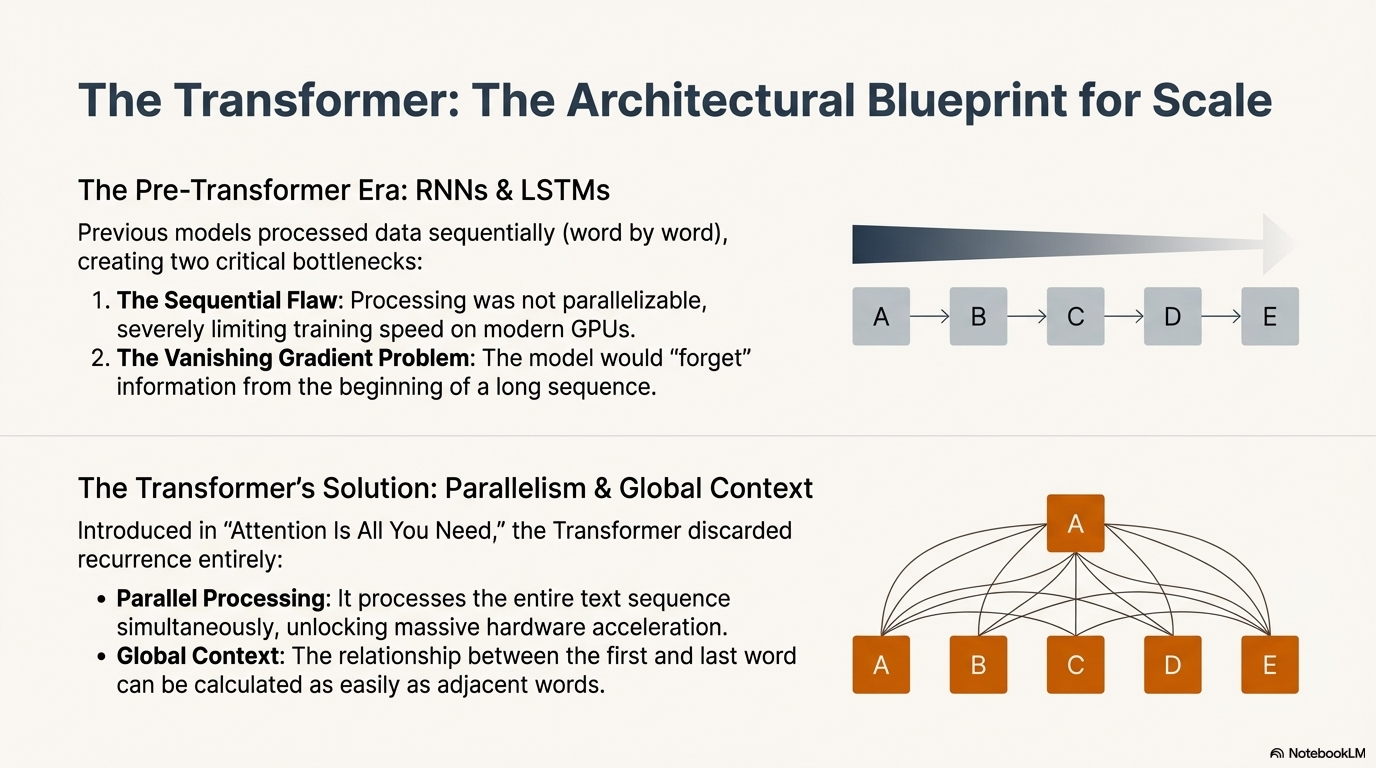
Before Transformers, language models primarily relied on RNNs and LSTMs. These models processed data sequentially—word by word, from left to right.17
4.1.1 The Sequential Flaw
To understand the last word in a paragraph, an RNN had to process every preceding word in order. This created a massive computational bottleneck.
- No Parallelism: Because the processing of word $t$ depended on the state of word $t-1$, computations could not be parallelized across the thousands of cores in a modern GPU. This severely limited the speed of training.18
- Linear Complexity: The time complexity for an RNN is $O(n)$, meaning processing time grows linearly with sequence length.
4.1.2 The Vanishing Gradient Problem
RNNs struggled with "long-term dependency." In a long paragraph, the model would essentially "forget" the information from the beginning by the time it reached the end. The signal from the early words would dilute or vanish as it propagated through the network layers.20 This made it nearly impossible for RNNs to generate coherent long-form text.
4.2 The Transformer Solution: Parallelism and Attention
Transformers revolutionized the field by discarding recurrence entirely. Instead of processing sequentially, Transformers process the entire sequence of text simultaneously (in parallel).22
- Parallel Processing: Transformers can ingest a sentence of 100 words in a single step (conceptually), rather than 100 sequential steps. This allows for massive scaling on modern hardware.
- Global Context: Because the model sees all words at once, the distance between words becomes irrelevant. The relationship between the first word and the last word of a book can be calculated as easily as the relationship between two adjacent words.20
To handle the relationships between words without processing them in order, Transformers utilize a mechanism called Self-Attention.23
4.3 Deep Dive: The Self-Attention Mechanism
Self-attention is the mechanism that allows the model to weigh the importance of different words in a sequence relative to one another, regardless of their position.23 It enables the model to create a context-aware representation of every word.
4.3.1 Analogy: The Cocktail Party
Imagine being at a loud cocktail party (the input sequence). You want to focus on a specific conversation (the target). To do this, you "attend" to the voice of your friend and "ignore" the background noise, even if the noise is loud or nearby. Self-attention allows the model to dynamically "turn up the volume" on relevant words and "tune out" irrelevant ones for each token it processes.21
- In an RNN, you would have to listen to every conversation in the room in order, one by one.
- In a Transformer, you can listen to everyone simultaneously and filter for the specific voice that matters to your current thought.21
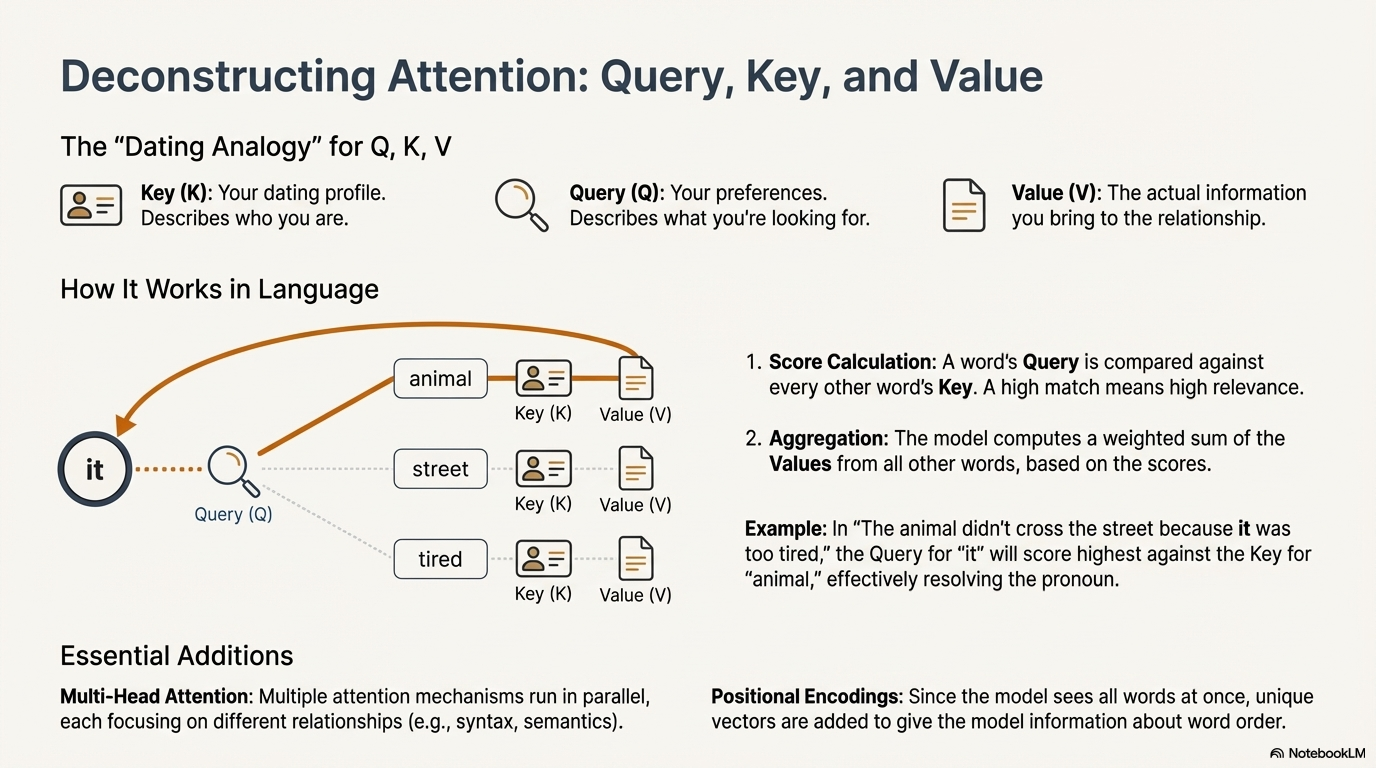
4.3.2 The Mechanism: Query, Key, and Value (Q, K, V)
The mathematical implementation of self-attention relies on three vectors generated for every token: Query (Q), Key (K), and Value (V).25
The Dating Analogy 27:
To understand these vectors, consider a matchmaking scenario:
- Key (K): Your profile. It describes who you are (e.g., "I am 5'10", like swimming, and have firewood").
- Query (Q): Your preference. It describes what you are looking for (e.g., "I want someone tall who likes outdoors").
- Value (V): The actual "substance" or information you bring to the relationship.
The attention mechanism works by comparing your Query against everyone else's Key.
- Score Calculation: The model calculates the dot product of $Q$ (what you want) and $K$ (what others have).
- Attention Weights: If $Q$ and $K$ align (high similarity), the score is high. This means you "pay attention" to that person.
- Aggregation: The model computes a weighted sum of the Values (V) of all the people you paid attention to.
In the context of language:
- The word "it" (Query) might look for a noun (Key) that appeared earlier in the sentence to resolve what "it" refers to.
- If the sentence is "The animal didn't cross the street because it was too tired," the Query for "it" will match strongly with the Key for "animal" and weakly with "street." The model effectively learns that "it" = "animal" in this context.15
4.3.3 Multi-Head Attention
Language is complex and ambiguous. A single relationship is rarely enough to understand a sentence. To capture multiple types of relationships simultaneously, Transformers use Multi-Head Attention.25
This is analogous to having multiple "search engines" running at once:
- Head 1 might focus on syntax (subject-verb agreement).
- Head 2 might focus on semantics (synonyms and definitions).
- Head 3 might focus on long-term context (pronoun resolution).
The outputs of these independent heads are concatenated and processed, providing the model with a rich, multi-perspective understanding of the text.29
4.4 Positional Encoding
Because Transformers process all words simultaneously in parallel, they have no inherent sense of order. Unlike RNNs, which implicitly know that "word 1" comes before "word 2," a Transformer sees a "bag of words" all at once.
To solve this, Positional Encodings are added to the token embeddings. These are unique mathematical vectors (often using sine and cosine functions) that are added to the word embeddings to give the model information about the relative position of each token in the sequence. This ensures the model can distinguish "The dog bit the man" from "The man bit the dog".25
4.5 Architectural Variants: Encoder vs. Decoder
The original Transformer paper proposed an architecture with two parts: an Encoder (for reading and processing input) and a Decoder (for generating output).31
- Encoder-Only (e.g., BERT): These models use only the encoder stack. They are "bidirectional," meaning they can look at a word and see both the words that come before it and after it simultaneously. They excel at understanding, classification, and sentiment analysis—discriminative tasks.
- Decoder-Only (e.g., GPT): These models use only the decoder stack. They are "autoregressive," meaning they are masked so they can only see the words that came before the current position. They cannot "cheat" by seeing the future. This architecture is the standard for generative text tasks.31
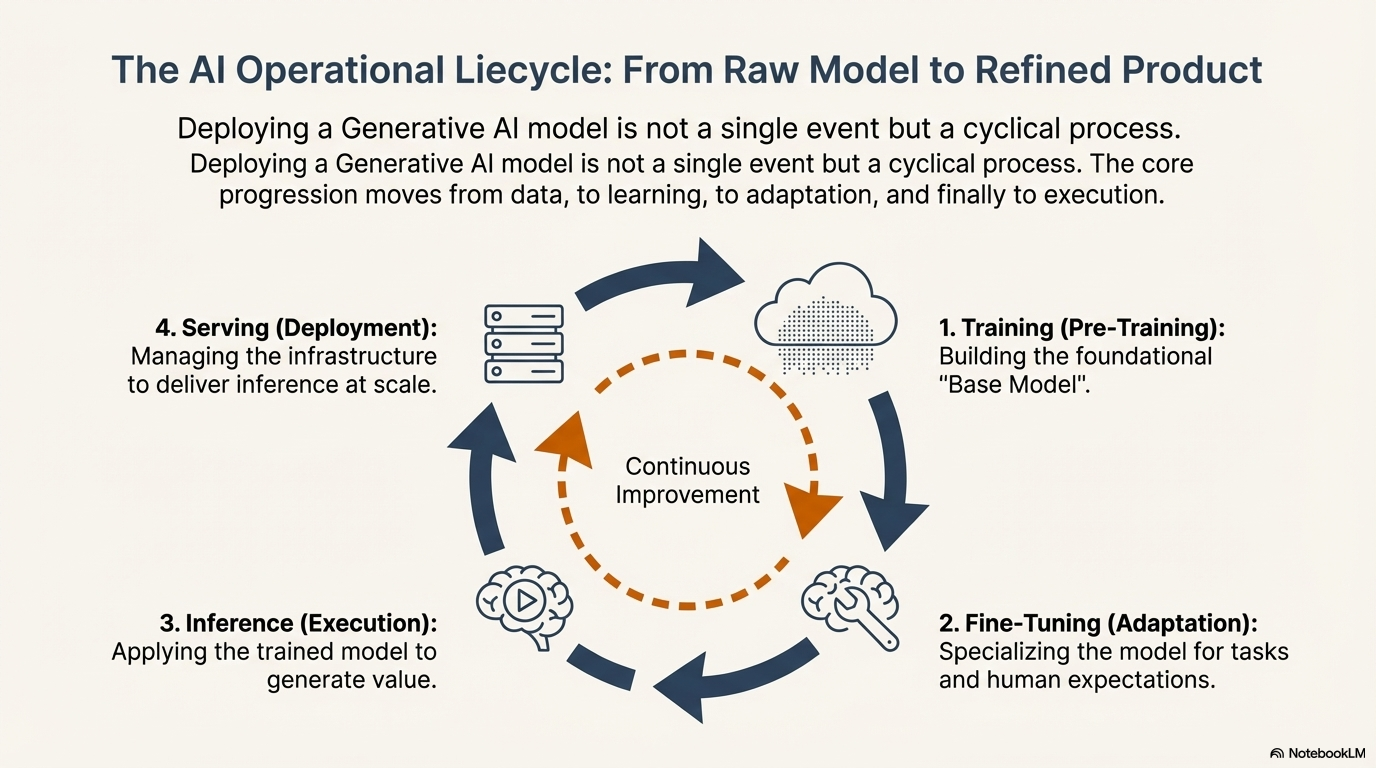
5. The AI Operational Cycle
Deploying a Generative AI model is not a single event but a cyclical lifecycle. While various frameworks define this lifecycle differently—some using 4 stages, others up to 7—the core progression remains consistent: from data to learning, to adaptation, and finally to execution.
The following analysis synthesizes the lifecycle into four primary operational stages, while incorporating the broader scoping and refinement phases recognized in enterprise frameworks.32
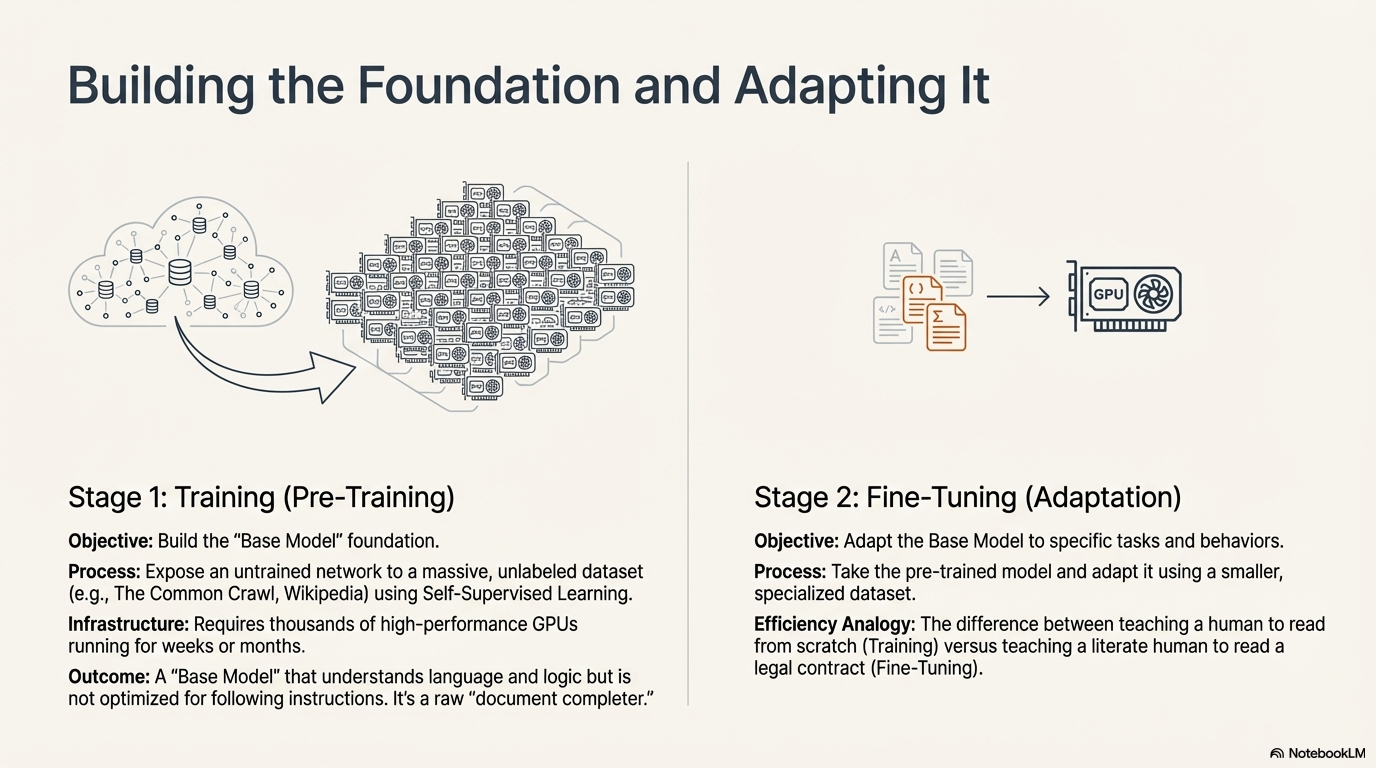
Stage 1: Training (Pre-Training)
Objective: Build the "Base Model" foundation.9
Training is the most computationally intensive phase of the lifecycle. It involves exposing the untrained neural network (which starts with random weights) to a massive dataset and iteratively adjusting those weights to minimize the error in next-token prediction.33
- Data Strategy: The dataset is vast and typically unlabeled (e.g., The Common Crawl, Wikipedia, GitHub code repositories). This utilizes Self-Supervised Learning, where the data itself provides the labels. The sheer volume of data is critical; the model must see enough examples of language to statistically approximate the structure of human knowledge.13
- Computational Infrastructure: This phase requires clusters of thousands of high-performance GPUs (e.g., NVIDIA H100s) running for weeks or months. It is an energy-intensive process that results in a static artifact: the pre-trained model weights.
- Outcome: The result is a "Base Model" (or Foundation Model). This model understands language, logic, and world knowledge. However, it is not yet optimized for following instructions or safe interaction. It functions as a raw "document completer." If you ask a base model "What is the capital of France?", it might complete the document with "and what is the capital of Germany?" rather than answering "Paris".9
Stage 2: Fine-Tuning (Adaptation)
Objective: Adapt the Base Model to specific tasks, domains, and human behavioral expectations.9
Because the base model is a raw statistical engine, it requires refinement to become a useful product. Fine-tuning acts as a shortcut to training; instead of training from scratch, developers take the powerful pre-trained model and adapt it using a smaller, specialized dataset.9
- Task Adaptation: Fine-tuning can specialize a model for medical diagnosis, legal contract review, or computer code generation. This allows the model to learn task-specific details and jargon that were not prevalent in the general pre-training data.34
- Efficiency: This process typically requires significantly less data and compute than pre-training. It is the difference between teaching a human to read (Training) and teaching a literate human to read a legal contract (Fine-Tuning).9
(Note: A detailed breakdown of Fine-Tuning techniques, specifically SFT and RLHF, is provided in Section 6).
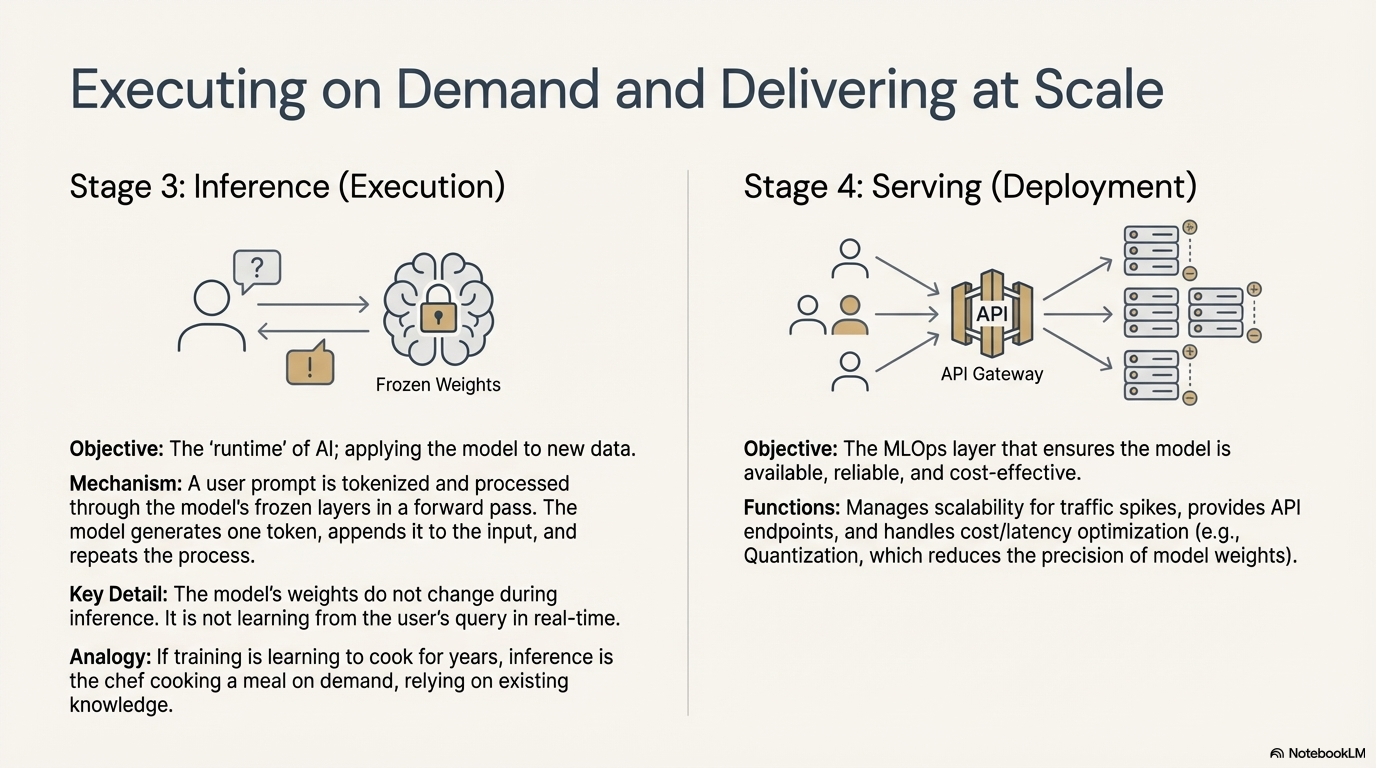
Stage 3: Inference (Execution)
Objective: Apply the trained model to new data to generate value.9
Inference is the "runtime" of AI. It is the moment the model stops learning and starts working. When a user sends a query to ChatGPT or a developer makes an API call to a coding assistant, they are triggering an inference process.
- Mechanism:
- Input Processing: The user's prompt is tokenized.
- Forward Pass: The input tokens are processed through the frozen layers of the model to calculate probabilities for the next token.
- Autoregression: The model generates one token. This new token is appended to the input sequence, and the whole sequence is fed back into the model to generate the second token. This loop continues until the model generates a "Stop" token or reaches a length limit.14
- The "Frozen" State: During inference, the model's weights do not change. It is not "learning" from the user's query in real-time (though the conversation history is stored in the context window to maintain coherence).9
- Analogy: If training is "learning to cook" by studying recipes for years, inference is the chef actually cooking a meal for a customer on demand. The chef relies on the knowledge they already have; they are not inventing a new culinary theory in the middle of the dinner rush.36
Stage 4: Serving (Deployment)
Objective: Manage the infrastructure that delivers inference at scale.9
Serving is the operational engineering layer (often called MLOps) that wraps the inference process. It ensures the model is available, reliable, and cost-effective.
- Scalability: Serving infrastructure must handle spikes in traffic. If millions of users query the model simultaneously, the system must dynamically allocate more GPU resources.9
- API Management: Models are typically exposed via endpoints (REST or gRPC). The serving layer manages authentication, rate limiting, and versioning (e.g., ensuring users can switch between Model V1 and Model V1.1 without downtime).
- Optimization: To reduce costs and latency, engineers use techniques like Quantization. This involves reducing the precision of the model's weights (e.g., from 16-bit floating point numbers to 8-bit integers). This reduces the memory footprint and speeds up calculation without significantly degrading the model's intelligence.34
The Extended Lifecycle: Scoping and Maintenance
Beyond the four core technical stages, enterprise frameworks often include "Scoping" and "Continuous Improvement" as critical phases.32
- Scoping: Before training begins, organizations must define the business problem, select the appropriate model size, and determine success metrics. This prevents the "build it and they will come" fallacy.
- Continuous Improvement: AI models can suffer from "drift" where their performance degrades as real-world data changes. Continuous monitoring of inference data allows developers to collect new examples, which can be fed back into the Fine-Tuning stage, creating a virtuous cycle of improvement.32
6. Advanced Fine-Tuning: SFT and RLHF
The distinction between a raw base model and a polished product like ChatGPT lies in the sophistication of the fine-tuning process. Modern GenAI deployment relies on two primary techniques: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). While both are "tuning" methods, they serve different operational goals and use different data structures.
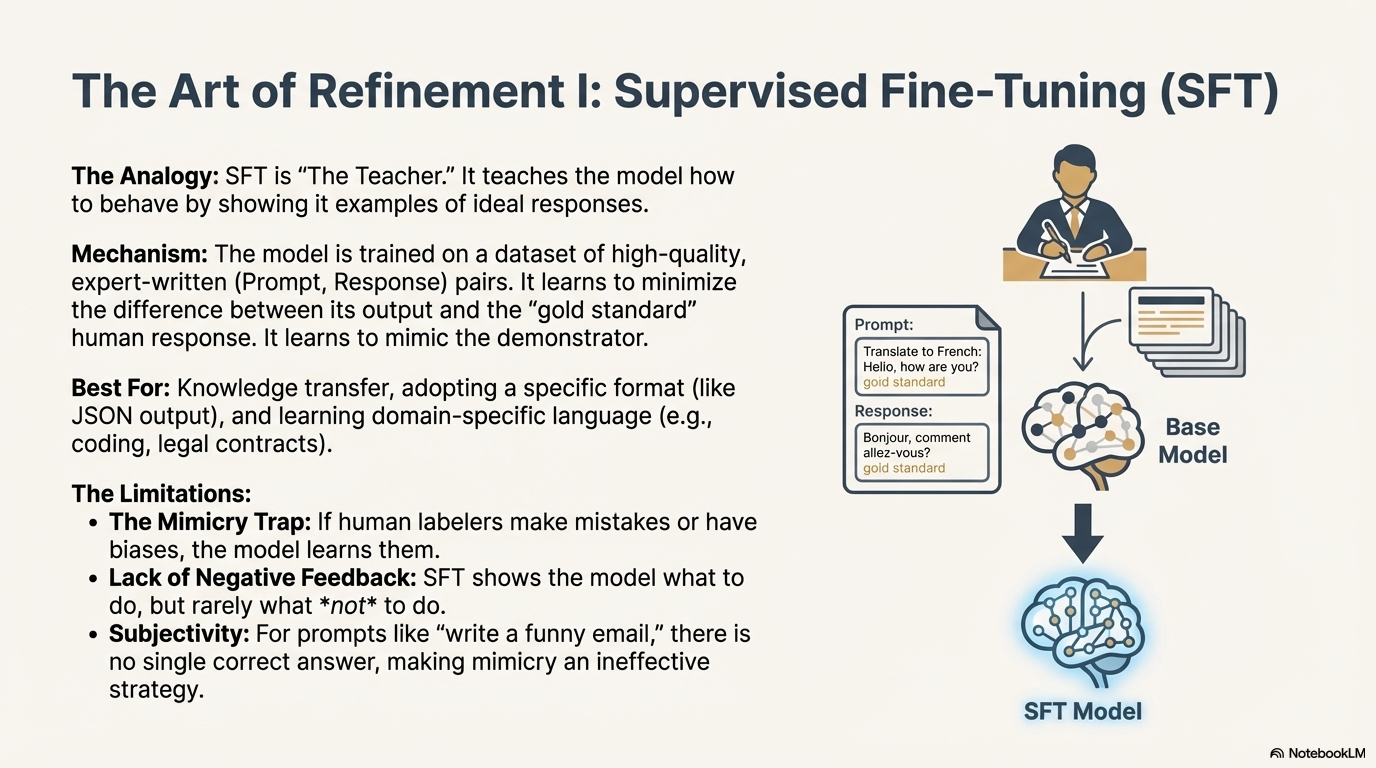
6.1 Supervised Fine-Tuning (SFT): The Teacher
SFT is the process of teaching the model how to respond to prompts by showing it examples of ideal behavior.37
6.1.1 Mechanism and Data
SFT utilizes a dataset of labeled examples, typically formatted as (Prompt, Response) pairs.
- Data Source: These examples are often written by human experts or curated from high-quality sources. For example, to train a model to code, the dataset would contain {Question: "Write a Python function to sort a list", Answer: "def sort_list(x):..."}.
- Process: The model is trained to minimize the difference between its own output and the "gold standard" human response provided in the dataset. It is essentially learning to mimic the style, format, and tone of the demonstrator.38
6.1.2 The Limitations of SFT
While SFT is excellent for knowledge transfer and formatting (e.g., forcing the model to output JSON), it has limitations:
- The Mimicry Trap: The model learns to copy the human labelers. If the labelers make mistakes, the model learns those mistakes (hallucinations).
- Lack of Negative Feedback: SFT only shows the model what to do. It rarely shows the model what not to do.
- Subjectivity: For creative prompts like "Write a funny email," there is no single "correct" answer. SFT struggles to capture the nuance of human preference in subjective domains.38
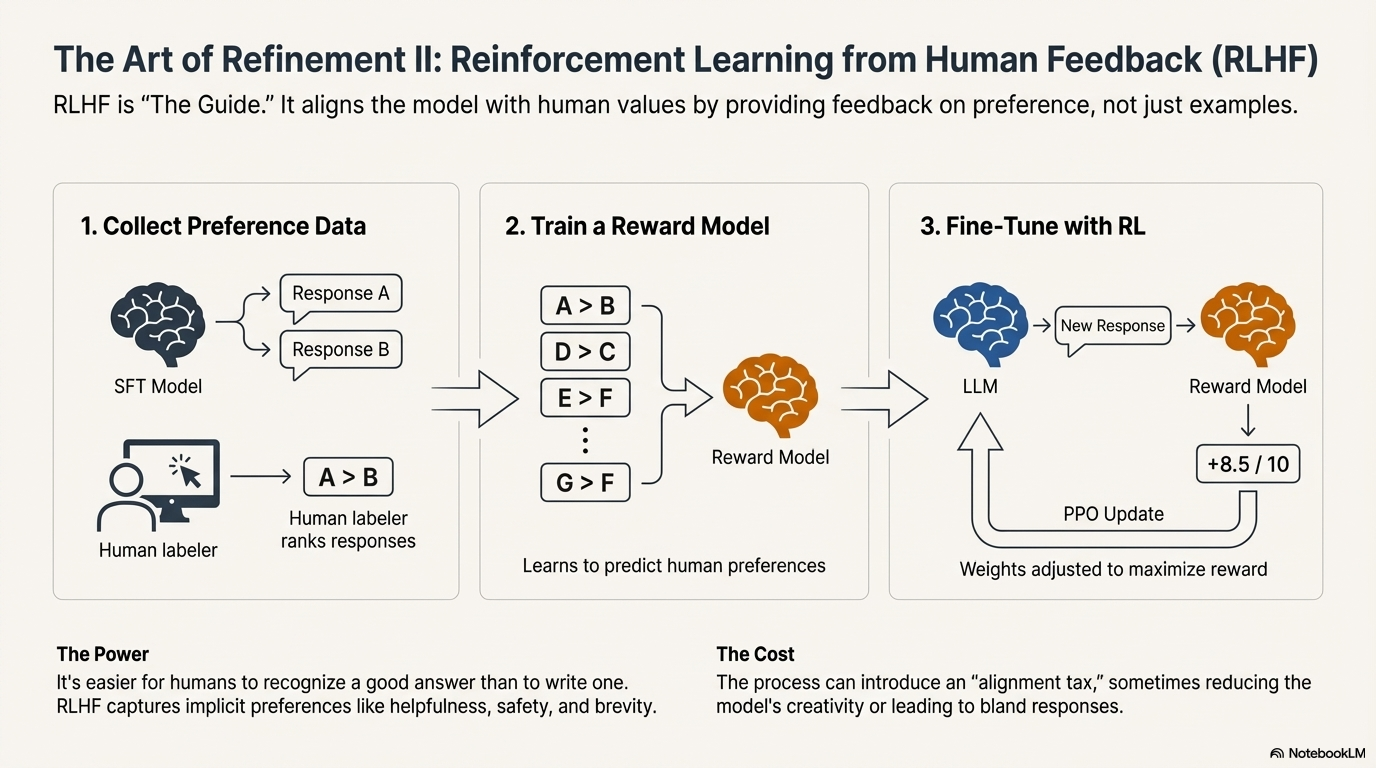
6.2 Reinforcement Learning from Human Feedback (RLHF): The Guide
RLHF addresses the limitations of SFT by introducing a feedback loop based on preference rather than mimicry. It aligns the model with human values like safety, helpfulness, and brevity.40
6.2.1 The RLHF Pipeline
The RLHF process is a multi-step workflow that usually follows SFT 39:
- Preference Data Collection: The SFT model generates multiple responses to a single prompt. Human labelers do not write the answer; instead, they rank the model's outputs (e.g., "Response A is better than Response B").
- Reward Model Training: A separate AI model (the Reward Model) is trained on this ranking data. Its job is to predict how a human would rate any given piece of text. It acts as a digital proxy for human preference.43
- Reinforcement Learning (PPO): The main language model generates text. The Reward Model scores the text. The main model then updates its weights to maximize this reward score, typically using an algorithm called Proximal Policy Optimization (PPO).41
6.2.2 The Power of Human Feedback
RLHF is powerful because it is easier for humans to recognize a good answer than to write one. It captures implicit preferences—such as "don't be too verbous," "don't be sycophantic," or "refuse dangerous requests politely"—that are difficult to encode in an SFT dataset.38
However, RLHF introduces the "alignment tax." Pushing the model to be safe and consistent can sometimes reduce its creativity or "temperature," leading to repetitive or bland responses.44
6.2.3 The Role of Human Labelers
Human labelers are the unsung heroes of the RLHF process. They define the "ground truth" of alignment. Their biases, cultural values, and understanding of instructions directly shape the "personality" and safety boundaries of the final model. If labelers consistently rate polite but incorrect answers higher than rude but correct answers, the model will learn to prioritize politeness over truth.45
RLHF is also being applied to other modalities, such as image generation, where human feedback helps correct visual artifacts or align images with prompt intent.47
6.3 SFT vs. RLHF: A Comparison
38
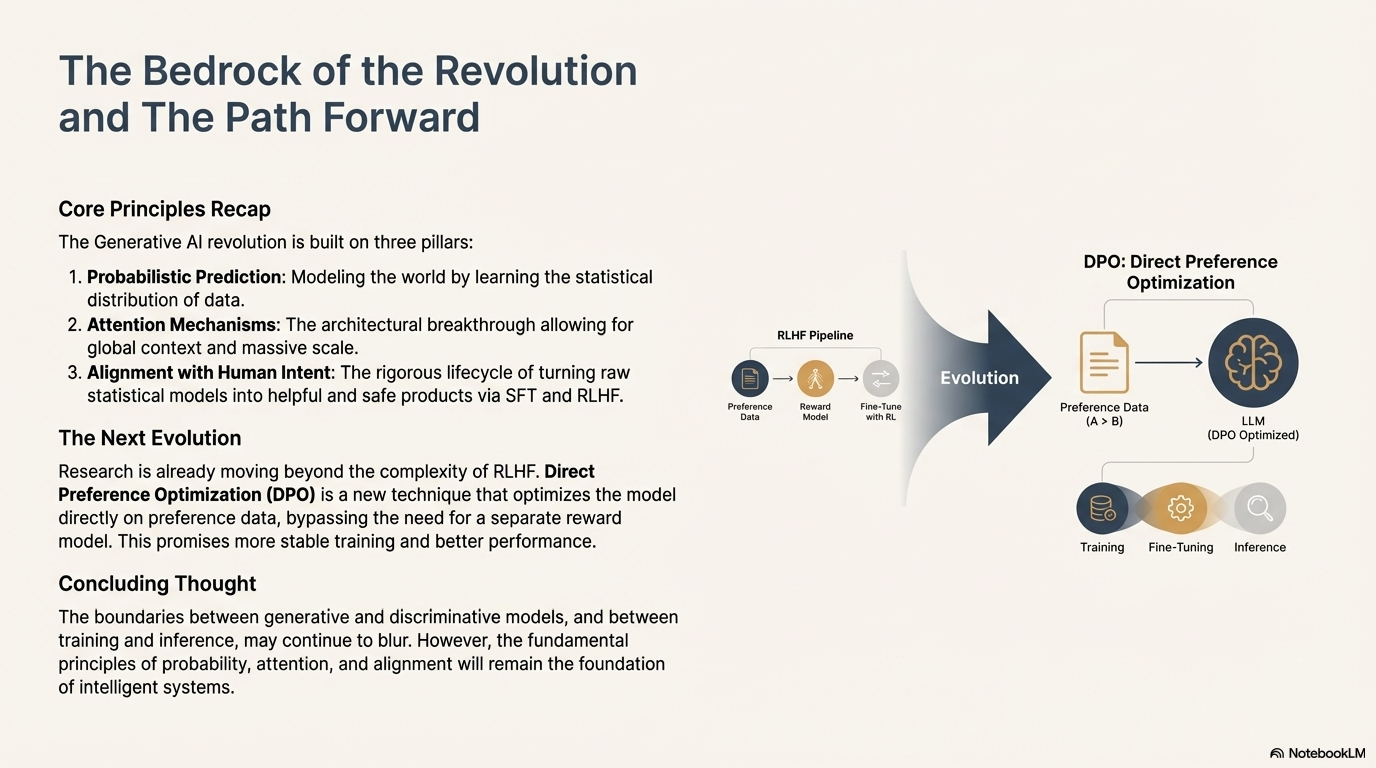
6.4 Future Directions: Direct Preference Optimization (DPO)
Recent research suggests that the complexity of RLHF—specifically the need to train a separate Reward Model—can be bypassed. Direct Preference Optimization (DPO) is a new technique that optimizes the model directly on the preference data (the rankings) without the intermediate step of a reward model. This stabilizes training and prevents overfitting, representing the next evolution in model tuning.48
Conclusion
The transition from discriminative to generative AI marks a watershed moment in the history of computing. By moving from models that classify existing data to models that model the probability distribution of the world's information, we have unlocked capabilities that mimic human creativity and reasoning.
The Transformer architecture provided the mechanical means to break the sequential processing bottleneck of the past, allowing models to scale to trillions of parameters and learn from internet-scale datasets. The Operational Lifecycle—from the brute-force computation of pre-training to the delicate behavioral adjustments of SFT and RLHF—provides the rigorous framework required to turn these mathematical curiosities into reliable, scalable products.
As we look forward, the distinction between "Training" and "Inference" may blur with continuous learning, and the boundaries of "Generative" and "Discriminative" may merge as systems become self-critiquing agents. However, the fundamental principles outlined here—probabilistic prediction, attention mechanisms, and the alignment of machine objectives with human intent—remain the bedrock of the Generative AI revolution.
Further Reading
- Analogy for Generative AI vs Discriminative AI - MikeBerggren.com, accessed December 11, 2025, https://www.mikeberggren.com/generative-ai-vs-discriminative-ai
- Generative artificial intelligence - Wikipedia, accessed December 11, 2025, https://en.wikipedia.org/wiki/Generative_artificial_intelligence
- The Surprising Power of Next Word Prediction: Large Language Models Explained, Part 1 | Center for Security and Emerging Technology, accessed December 11, 2025, https://cset.georgetown.edu/article/the-surprising-power-of-next-word-prediction-large-language-models-explained-part-1/
- LLM Transformer Model Visually Explained - Polo Club of Data Science, accessed December 11, 2025, https://poloclub.github.io/transformer-explainer/
- Background: What is a Generative Model? | Machine Learning - Google for Developers, accessed December 11, 2025, https://developers.google.com/machine-learning/gan/generative
- What is the difference between a generative and a discriminative algorithm? [closed], accessed December 11, 2025, https://stackoverflow.com/questions/879432/what-is-the-difference-between-a-generative-and-a-discriminative-algorithm
- [D] Need some serious clarifications on Generative model vs Discriminative model - Reddit, accessed December 11, 2025, https://www.reddit.com/r/MachineLearning/comments/k0t400/d_need_some_serious_clarifications_on_generative/
- Generative models vs Discriminative models for Deep Learning. - Turing, accessed December 11, 2025, https://www.turing.com/kb/generative-models-vs-discriminative-models-for-deep-learning
- What is AI inference? How it works and examples | Google Cloud, accessed December 11, 2025, https://cloud.google.com/discover/what-is-ai-inference
- Generative AI vs Discriminative AI: What's the Difference - Addepto, accessed December 11, 2025, https://addepto.com/blog/generative-ai-vs-discriminative-ai-whats-the-difference-and-why-it-matters/
- Generative vs Discriminative Models: Differences & Use Cases - DataCamp, accessed December 11, 2025, https://www.datacamp.com/blog/generative-vs-discriminative-models
- Generative vs Discriminative AI: Who's the Real AI Champion? - Data Science Dojo, accessed December 11, 2025, https://datasciencedojo.com/blog/generative-vs-discriminative-ai/
- How Large Language Models Learn to Predict | Medium, accessed December 11, 2025, https://medium.com/@pacosun/how-large-language-models-learn-to-predict-1edd6ab8d0d7
- L-1 | Understanding LLMs — Conceptually & Mathematically | Lecture 1 | LLMs Course, accessed December 11, 2025, https://www.youtube.com/watch?v=0qr6IcWJ-7Y
- Self-Attention: The Simple Mechanism That Made ChatGPT Possible | by Debasish Das, accessed December 11, 2025, https://pub.towardsai.net/transformer-architecture-self-attention-3f947540871d
- Researchers Are Getting Really Creative Training LLMs [Token Order Prediction], accessed December 11, 2025, https://www.youtube.com/watch?v=sgIB7l6hW3Q
- Transformer vs RNN in NLP: A Comparative Analysis - Appinventiv, accessed December 11, 2025, https://appinventiv.com/blog/transformer-vs-rnn/
- Why is it said that the transformer is more parallelizable than RNN's? - Reddit, accessed December 11, 2025, https://www.reddit.com/r/deeplearning/comments/14ad4of/why_is_it_said_that_the_transformer_is_more/
- Why is it said that the transformer is more parallelizable than RNN's? - Reddit, accessed December 11, 2025, https://www.reddit.com/r/MLQuestions/comments/14aedwk/why_is_it_said_that_the_transformer_is_more/
- Why does the transformer do better than RNN and LSTM in long-range context dependencies?, accessed December 11, 2025, https://ai.stackexchange.com/questions/20075/why-does-the-transformer-do-better-than-rnn-and-lstm-in-long-range-context-depen
- Transformer via Analogies - by Ashutosh Kumar - Medium, accessed December 11, 2025, https://medium.com/@ashu1069/transformer-via-analogies-4e162c8601b6
- The Ultimate Guide: RNNS vs. Transformers vs. Diffusion Models | by Jason Roell | Medium, accessed December 11, 2025, https://medium.com/@roelljr/the-ultimate-guide-rnns-vs-transformers-vs-diffusion-models-5e841a8184f3
- A Beginner's Guide to Self-Attention in Transformers | by Nacho Zobian | Medium, accessed December 11, 2025, https://medium.com/@nachozobian/a-beginners-guide-to-self-attention-in-transformers-baf71a971efd
- Cracking ML Interviews: Self-Attention Mechanism (Question 14), accessed December 11, 2025, https://www.youtube.com/watch?v=3oGu6fg1AA8
- Transformer Architecture Explained With Self-Attention Mechanism - Codecademy, accessed December 11, 2025, https://www.codecademy.com/article/transformer-architecture-self-attention-mechanism
- Deep Dive into Self-Attention by Hand✍︎ | Towards Data Science, accessed December 11, 2025, https://towardsdatascience.com/deep-dive-into-self-attention-by-hand-%EF%B8%8E-f02876e49857/
- [D] How to truly understand attention mechanism in transformers? : r/MachineLearning - Reddit, accessed December 11, 2025, https://www.reddit.com/r/MachineLearning/comments/qidpqx/d_how_to_truly_understand_attention_mechanism_in/
- Self-Attention: Understanding with Easy Analogies | by Mubashir Iqbal | Medium, accessed December 11, 2025, https://medium.com/@mubashiri656/transformers-simplified-understanding-self-attention-with-easy-analogies-9464585459ce
- How Transformers Work: A Detailed Exploration of Transformer Architecture - DataCamp, accessed December 11, 2025, https://www.datacamp.com/tutorial/how-transformers-work
- How LLM Predict the Next Token - Technical Knowledge Base, accessed December 11, 2025, https://ersantana.com/llm/how-llms-talk
- Gen AI Part 4 - Understanding Transformers, Self-Attention, and GPT vs. BERT, accessed December 11, 2025, https://www.youtube.com/watch?v=Gy84sFW5Uv8
- Generative AI lifecycle - AWS Documentation, accessed December 11, 2025, https://docs.aws.amazon.com/wellarchitected/latest/generative-ai-lens/generative-ai-lifecycle.html
- What Is Model Training? | IBM, accessed December 11, 2025, https://www.ibm.com/think/topics/model-training
- What Is the AI Development Lifecycle? - Palo Alto Networks, accessed December 11, 2025, https://www.paloaltonetworks.com/cyberpedia/ai-development-lifecycle
- What Is AI Inference? - Oracle, accessed December 11, 2025, https://www.oracle.com/artificial-intelligence/ai-inference/
- Unleashing the Potential of ML: A Beginner's Guide to ML Inference Servers | by Senthil Raja Chermapandian | Medium, accessed December 11, 2025, https://medium.com/@senthilrch/ml-inference-servers-explained-f8fb24e3ebe5
- accessed December 11, 2025, https://bluedot.org/blog/what-is-supervised-fine-tuning#:~:text=SFT%20teaches%20a%20model%20to,using%20SFT%20on%20its%20own.
- What is supervised fine-tuning? - BlueDot Impact, accessed December 11, 2025, https://bluedot.org/blog/what-is-supervised-fine-tuning
- Supervised Fine-Tuning vs. RLHF: How to Choose the Right Approach to Train Your LLM, accessed December 11, 2025, https://invisibletech.ai/blog/supervised-fine-tuning-vs-rlhf-how-to-choose-the-right-approach-to-train-your-llm
- What Are Large Language Models (LLMs)? - IBM, accessed December 11, 2025, https://www.ibm.com/think/topics/large-language-models
- The 5 Steps of Reinforcement Learning with Human Feedback - Appen, accessed December 11, 2025, https://www.appen.com/blog/the-5-steps-of-reinforcement-learning-with-human-feedback
- Reinforcement learning from human feedback - Wikipedia, accessed December 11, 2025, https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback
- What is RLHF? - Reinforcement Learning from Human Feedback Explained - AWS, accessed December 11, 2025, https://aws.amazon.com/what-is/reinforcement-learning-from-human-feedback/
- Fine-Tuning vs. Human Guidance: SFT and RLHF in Language Model Tuning - Medium, accessed December 11, 2025, https://medium.com/@veer15/fine-tuning-vs-human-guidance-sft-and-rlhf-in-language-model-tuning-6ad54e1ba628
- What Is Reinforcement Learning From Human Feedback (RLHF)? - IBM, accessed December 11, 2025, https://www.ibm.com/think/topics/rlhf
- Illustrating Reinforcement Learning from Human Feedback (RLHF) - Hugging Face, accessed December 11, 2025, https://huggingface.co/blog/rlhf
- Enriching Image Labeling with Reinforcement Learning from Human Feedback - Sapien, accessed December 11, 2025, https://www.sapien.io/blog/enriching-image-labeling-with-reinforcement-learning-from-human-feedback
- Fine-Tuning Techniques - Choosing Between SFT, DPO, and RFT (With a Guide to DPO), accessed December 11, 2025, https://cookbook.openai.com/examples/fine_tuning_direct_preference_optimization_guide