Chapter 1. Introduction: Why AI Loops Are the New Engineering Surface
In the early 2020s, the dominant paradigm for interacting with Large Language Models (LLMs) was the single turn: the "prompt." Success was measured by how much intent a human could pack into a single text block. By 2024, this evolved into "chaining," and by early 2025, it stabilized into "vibe coding." But as we move into mid-2026, the ceiling of what a single prompt can achieve has been reached.
The new engineering surface is not the prompt; it is the loop.
We have entered the era where the primary task of a software engineer or product manager is no longer writing instructions for a model to follow once, but designing the autonomous systems—the harnesses, evaluators, and feedback cycles—within which a model can iteratively correct its own failures. This chapter defines why loop engineering is the inevitable successor to everything that came before it.
1.1. From Prompting to Loop Engineering

The transition from "Prompt Engineering" to "Loop Engineering" marks a fundamental shift in how we leverage compute. Prompt engineering was a linguistic exercise; it relied on "jailbreaking" the model’s internal weights through clever phrasing. Loop engineering, as framed by Jonas Steinberger and Addy Osmani in their seminal June 2026 essay "Loop Engineering: The Architecture of Autonomous Iteration," treats the LLM as a single component within a larger, self-correcting state machine.
Steinberger and Osmani argue that the "unit of value" in AI has shifted from the response to the trajectory. If a model produces a bug on turn one, it doesn’t matter—as long as the system detects the bug, executes a test, and fixes the error by turn four. The goal of the engineer is to design the boundaries and the objective functions of that four-turn cycle.
This discipline stands on two pillars: Loop Engineering and Context Engineering. While Anthropic’s Sept 2025 post "Effective Context Engineering for AI Agents." focused on the "Horizontal" axis—how to package tools, documentation, and history into a 200k+ token window so the model knows at all times what it is doing—Loop Engineering focuses on the "Vertical" axis: the logic that determines what happens next after the model speaks.
A modern AI Loop looks like this:
graph TD
A[Intent/Goal] --> B[Planner]
B --> C[Action/Tool Use]
C --> D[Observation/Feedback]
D --> E{Success Criteria Met?}
E -- No --> B
E -- Yes --> F[Final Output]
D -- Error --> G[Self-Correction Loop]
G --> B
In this framework, the prompt is merely the "Plan" stage. The "Engineering" happens in the arrows. It happens in the Observation phase—parsing the output of a CLI, a PDF parser, or a revenue dashboard—and feeding that back into the model in a way that triggers a course correction.
1.2. The Vibe Coding to Agentic Engineering Arc
To understand where we are, we must look at how we got here. In February 2025, Andrej Karpathy coined the term "vibe coding" in a viral tweet, describing a workflow where the developer spends less time writing syntax and more time "vibing" with the model—broadly steering the direction of the code until it "feels" right. It was an admission that models like Claude 3.5 Sonnet and early GPT-5 iterations had become good enough to handle the implementation details if given the right atmospheric direction.
However, "vibing" lacks rigor. It works for a Todo list app or a simple React component, but it falls apart at the architectural level. By his Sequoia 2026 talk, Karpathy reframed this: the "vibes" were actually the precursor to Agentic Engineering. He argued that the role of the developer was orphaning the "coder" role to become the "harness designer."
One-shot prompting plateaued because LLMs are statistically prone to "drift." In a vacuum, a model’s probability of making a fatal mistake increases with the complexity of the task. Loop-based systems, such as Devin (Cognition), Claude Code (Anthropic’s 2025 CLI), and the open-source variants inspired by Simon Willison’s "LLM-as-CLI" experiments, broke this ceiling by introducing Environment Feedback.
Consider the difference in these two approaches to a data migration task:
The One-Shot Approach (2023-2024):
"Write a Python script to migrate this legacy MySQL database to Postgres, handling the following schema changes..."
Result: A script that almost works but fails on a hidden edge case in the 400th row.
The Loop Approach (2025-2026):
# Pseudo-code for an Agentic Loop harness
def migration_loop(target_schema, sample_data):
plan = agent.generate_plan(target_schema)
while not testing_harness.passed(plan):
logs = testing_harness.run(plan, sample_data)
if logs.contains_errors():
# The 'Loop' logic returns context to the model
plan = agent.reflect_and_fix(plan, logs)
else:
break
return plan
The loop approach doesn't require the model to be perfect; it requires the harness to be honest. The history of tools like Cursor and Devin shows that the winner isn't the one with the smartest model, but the one who builds the fastest, most high-fidelity feedback loop between the model and the compiler (or the browser, or the terminal).
1.3. Why This Matters Beyond Coding
While software engineering is the "patient zero" for AI loops—thanks to the binary feedback of compilers and test suites—the patterns are rapidly colonizing every other vertical.
In Research and Analysis, loops prevent "hallucination ruts." Instead of asking an AI to "Summarize the latest trends in NVMe storage," a loop-engineered system uses the Model Context Protocol (MCP, Nov 2024) to search ArXiv, fetch three papers, extract contradictory claims, and then prompt the model specifically to resolve those contradictions. The loop doesn't stop until the "resolution score" meets a threshold.
In Operations and Sales, loops are replacing linear zaps or workflows. A loop can monitor a lead's response, check the CRM for historical context, simulate a response, have a second "critic" model evaluate if that response sounds too robotic, and then iterate until the "vibe check" passes.
The core thesis of this book is that The Loop is the Product.
- If you are a PM, you are designing the success criteria of the loop.
- If you are an Engineer, you are building the infrastructure (the MCP servers, the sandboxes) that allows the loop to execute.
- If you are a Founder, you are selling the reliability that only a closed-loop system can provide.
The transition from "AI as a feature" to "AI as a loop" is what separates the toys from the infrastructure. Projects like Terminal-Bench and SWE-bench (the benchmarks that finally forced us to admit models need tools) have proven that a model's "IQ" matters less than its "Agency"—its ability to use a tool, observe the error, and try again.
1.4. Who This Book Is For and How to Read It
This book is written for the "Builders of 2026." You likely already use an AI pair programmer and have integrated LLM APIs into your stack. You are past the "wow" phase of generative AI and are now hitting the "reliability wall."
This book is for:
- Founders and CTOs who need to move their product from "unreliable demo" to "enterprise-grade automation."
- Product Managers who need to define "Done" for an agent that creates its own paths.
- Software Engineers who want to master the architectural patterns of the post-prompt world.
How this book is structured:
- Foundations (Chapters 2-3): We dive into the Model Context Protocol (MCP) and how to build the "Sensory Nervous System" for your agents.
- Patterns (Chapters 4-6): We explore the "Planner-Critique," "Multi-Agent Orchestration," and "Self-Correction" loops.
- Infrastructure (Chapters 7-9): How to run these loops at scale—sandboxing, cost control (the "Token Budget"), and latency.
- Governance and Evals (Chapters 10-12): Why Simon Willison was right about "evals as unit tests" and how to measure a system that is non-deterministic.
We are moving away from the era of "Model-Centric" AI and into the era of "System-Centric" AI. It’s time to stop writing better prompts and start building better loops.
Key Takeaways
- Prompting is dead; loops are the replacement. The engineering surface has shifted from the input string to the execution cycle.
- The trajectories matter more than turns. A system is only as good as its ability to recover from a model's mistake.
- Loop Engineering is a discipline. It requires a mix of systems architecture, context engineering (Anthropic, 2025), and traditional testing.
- Vibe coding was a bridge. It moved us toward human-in-the-loop workflows, but "Agentic Engineering" is the rigorous destination for production systems.
- Feedback is the fuel. A loop without high-fidelity feedback (from a terminal, a browser, or an eval model) is just a very expensive hallucination.
Further Reading
- Steinberger, J. & Osmani, A. (June 2026). Loop Engineering: The Architecture of Autonomous Iteration. Osmani Engineering Essays.
- Karpathy, A. (Feb 2025). "The transition from coding to vibe coding." X/Twitter.
- Karpathy, A. (June 2025). "Software 3.0: The Agentic Revolution." YC AI Startup School.
- Anthropic. (Sept 2025). "Effective Context Engineering for AI Agents." Anthropic Engineering Blog.
- Anthropic. (Dec 2024). "Building Effective Agents." Anthropic Research.
- Willison, S. (2024-2025). "Series on LLM Evals and Tool Use." simonwillison.net.
- Cognition AI. (2024). "Devin: The First AI Software Engineer Post-Mortem." Cognition Technical Blog.
- Model Context Protocol (MCP) Specification. (Nov 2024). modelcontextprotocol.io.
- Jimenez, C. et al. (2024). "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" ArXiv.
Chapter 2. What an AI Loop Actually Is
The industry spent 2023 and 2024 obsessed with the "Chat" interface. We treated LLMs as sophisticated oracles—entities you ask a question, wait five seconds, and receive an answer. This is the one-shot paradigm. It is fragile, unpredictable, and ultimately unscalable for serious engineering.
By 2025, the consensus shifted toward loops. As Andrej Karpathy noted in his June 2025 YC AI Startup School talk, the "unit of value" in AI has moved from the token to the task. To accomplish a task, a model cannot simply speak; it must act, observe the consequences of that action, and correct its course. This chapter defines the technical boundaries of these loops and provides the vocabulary necessary to build them.
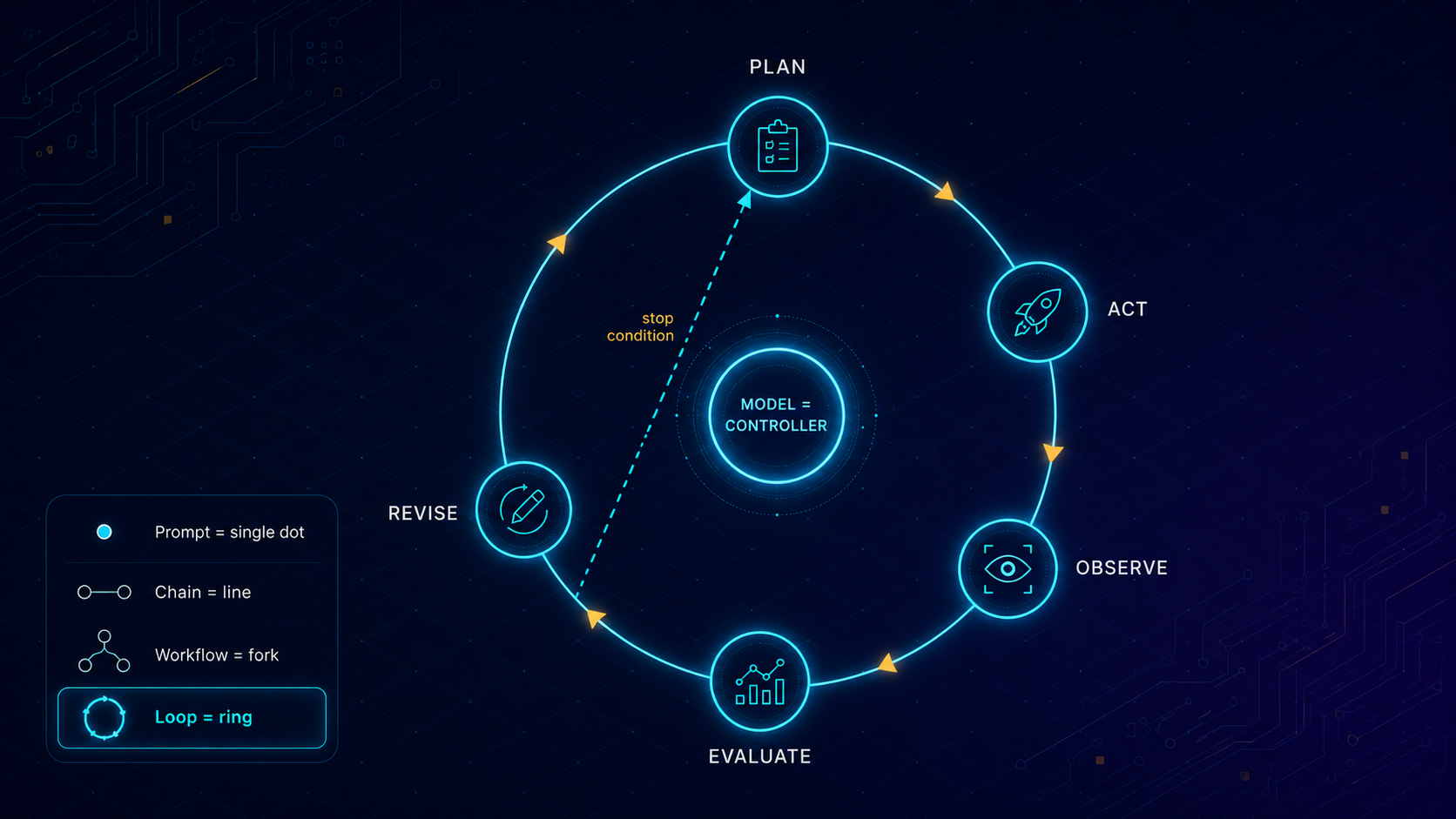
2.1. A Working Definition
An AI Loop is a closed cycle of execution where a model’s output is fed into a runtime environment, the results of that environment are captured as observations, and those observations are fed back into the model to inform the next step.
It is a state machine where the transitions are governed by probabilistic model inferences rather than static logic. In a loop, the model is not just a generator; it is a controller.
The Hierarchy of Agency
To build effectively, you must distinguish between four distinct patterns of model interaction. Confusing a "chain" for a "loop" is the primary reason many early agentic prototypes fail to reach production.
- The Prompt (One-Shot): Input $\rightarrow$ Model $\rightarrow$ Output. This is stateless and has no feedback mechanism. If the output is wrong, the process ends.
- The Chain (Directed Acyclic Graph): A sequence of prompts where the output of Prompt A is the input for Prompt B. This is "loops-lite," but it lacks a return path. It is brittle because an error in the first step propagates linearly.
- The Workflow (Branching): A chain with "if/else" logic. Hardcoded paths decide whether to call Model A or Model B. This is the domain of traditional RPA (Robotic Process Automation) augmented with LLMs.
- The Loop (Iterative): The model enters a cycle of Plan $\rightarrow$ Act $\rightarrow$ Observe $\rightarrow$ Evaluate $\rightarrow$ Revise. It does not exit until a objective-based stop condition is met or a resource budget is exhausted.
As Simon Willison argued in his mid-2025 essays on "Loop Engineering," the loop is the first pattern that displays emergent problem-solving. While a chain can follow a recipe, a loop can debug a failing test case it has never seen before.
2.2. The Anatomy of a Loop
A loop is more than just a while True: statement around an OpenAI API call. To move from a "vibe-based" script to a production system, you must architect the following eight components.
1. The Goal (The Objective)
The North Star. It must be specific and, ideally, verifiable. "Refactor the authentication logic" is a poor goal. "Refactor auth.py to use JWT instead of sessions while maintaining 100% test coverage" is a loopable goal.
2. The State (The Context)
The current representation of the world. In a coding loop (like Cursor or Claude Code), the state includes the file tree, the open buffers, and the console output. Management of state is the most difficult part of loop design; if the state grows too large, the model loses the "signal" in the "noise" (Anthropic, "Effective Context Engineering for AI Agents," Sept 2025).
3. The Model Call (The Reasoning Engine)
The LLM serves as the brain. Note that different models serve different roles within the same loop. You might use a "fast" model for tool selection and a "reasoning" model (like an O1 or Claude 3.5 Sonnet) for the central evaluation step.
4. Tools (The Actuators)
The functions the model can call. Following the Model Context Protocol (MCP) (released by Anthropic in Nov 2024), tools should be standardized interfaces that allow the model to interact with local files, databases, or web APIs.
5. Observations (The Feedback)
The output of the tool execution. If the model runs ls -la, the observation is the directory listing. If it runs a Python script that crashes, the observation is the stack trace. The loop's value is entirely dependent on the quality of these observations.
6. The Evaluator (The Judge)
A critical component often missing in "vibe-coded" agents. This is a secondary logic gate—often a separate model call or a hardcoded test suite—that determines if the last action moved the system closer to the goal.
7. Memory (The Log)
A record of past attempts. Without memory, loops fall into "infinite recursion" where the model tries the same failing command three times in a row.
8. Stop Condition & Budget
The safety rails. A loop must terminate when the goal is met, a "max iterations" limit is reached, or a token/dollar budget is exceeded.
The Harness vs. The Scaffold
In our engineering practice, we distinguish between these two:
- The Scaffold: The system prompt and instructions given to the model to help it structure its thinking (e.g., "Think step-by-step," "Use the Thought/Action/Observation format").
- The Harness: The Python/TypeScript code that handles the
whileloop, captures the tool output, persists the history to a database, and manages error handling.
The harness is the "physical" infrastructure; the scaffold is the "mental" framework.
graph TD
A[Goal Defined] --> B[Generate Plan]
B --> C{Action Needed?}
C -- Yes --> D[Execute Tool]
D --> E[Capture Observation]
E --> F[Evaluate Progress]
F --> B
C -- No --> G[Final Result]
F -- Failure Threshold --> H[Exit with Error]
2.3. Inner Loops vs. Outer Loops
In "Loop Engineering" (June 2026), Steinberger and Osmani introduced a critical distinction that has since become the standard for agentic architecture: the separation of Inner and Outer loops.
The Inner Loop: Per-Turn Reasoning
The inner loop is what happens inside a single task execution. It is the model deciding: "I need to read package.json, then I will run npm install."
- Focus: Speed, tool-calling accuracy, and syntax.
- Benchmark: SWE-bench (Software Engineering Benchmark).
- Common Failure: A "hallucination loop" where the model invents a tool that doesn't exist.
The Outer Loop: The Supervisor
The outer loop manages the lifecycle of the task. It answers questions the inner loop is too "close" to the problem to see:
- "This task has been running for 10 minutes; should I kill it?"
- "The inner loop is stuck in a circle; should I reset the state and try a different strategy?"
- "The goal has changed based on new user input; update the plan."
If the inner loop is the worker, the outer loop is the manager.
Most failures in late 2024 agents (like early versions of Devin or open-source clones) occurred because they lacked a robust outer loop. They were brilliant at individual steps but had no "executive function." They would happily spend $50 of API credits trying to fix a typo in a file that didn't exist.
Why Hype vs. Reality Diverge
The "hype" usually lives in the inner loop: amazing demos of a model writing 50 lines of code in one go. However, the "utility" lives in the outer loop: the system's ability to recover from a 404 error, a rate limit, or a logic bug without human intervention.
As Karpathy famously tweeted in Feb 2025 regarding "vibe coding": The magic isn't in the model getting it right the first time. The magic is the system staying in the loop until it is right.
Example: A Loop Implementation in TypeScript
This is a simplified harness for a file-editing loop using an MCP-like interface.
async function agenticLoop(goal: string, maxIterations: number = 10) {
let state = { status: "planning", history: [], currentTask: goal };
let budget = 0;
for (let i = 0; i < maxIterations; i++) {
// 1. The Model Call (Inner Loop Reasoning)
const response = await model.generate({
system: SCAFFOLD_PROMPT,
prompt: `Goal: ${goal}. History: ${state.history}`,
tools: [fileReader, fileWriter, terminalExecutor]
});
// 2. The Stop Condition
if (response.type === 'complete') return response.content;
// 3. Action & Observation
for (const action of response.actions) {
const observation = await toolHarness.execute(action);
state.history.push({ action, observation });
// 4. Outer Loop Evaluation
const evaluation = await evaluator.check(state);
if (evaluation.isStuck) {
console.warn("Outer Loop: Detection of infinite loop. Resetting strategy.");
state.history.push("System note: You are stuck. Try a different approach.");
}
}
budget += response.usage.cost;
if (budget > MAX_BUDGET) throw new Error("Budget exceeded");
}
}
2.4. Required Reading
To master the design of these systems, the following texts are foundational. They track the evolution from simple "tool use" to the complex "harnessing" required for autonomous operations.
- Anthropic, "Building Effective Agents." (Dec 2024): The seminal guide on moving from prompts to agentic workflows. It defines the basic patterns of routing and orchestration.
- Simon Willison, "Designing Agentic Loops" (May 2025): A practitioner's view on why the "harness" is more important than the "prompt." Willison explores the necessity of evals in long-running loops.
- Anthropic, "Effective Harnesses for Long-Running Agents." (Sept 2025): Technical documentation on context management, "summarization-as-memory," and preventing state bloat in loops that last hours or days.
- Steinberger & Osmani, "Loop Engineering: Architecting Autonomous Systems" (June 2026): The primary text on the Inner/Outer loop distinction and "Budget-Aware Inference."
- Terminal-Bench Postmortem (March 2025): Analysis of why models fail when given raw terminal access, highlighting the need for "Observation Cleaning."
Key Takeaways
- Loops are cycles, not sequences. A loop requires a feedback path where observations from the real world inform the next model call.
- The Harness is the product. While the model provides the "intelligence," the surrounding code (the harness) provides the reliability, error handling, and budget management.
- Distinguish Inner and Outer loops. Use the inner loop for task execution and a supervising outer loop for lifecycle management and strategy correction.
- Evaluators are non-negotiable. A loop without an automated evaluator is just a very expensive way to generate a hallucination.
- Tool standardization is crucial. Use protocols like MCP to ensure your model's tools are modular and testable outside the loop.
- Observations must be curated. Directly dumping massive log files into a model's context will cause it to lose focus. The harness must clean and summarize observations.
Further Reading
- Anthropic. (2024, December). Building Effective Agents. Anthropic Engineering Blog.
- Karpathy, A. (2025, February). Vibe Coding and the Future of Software. Twitter/X.
- Karpathy, A. (2025, June). Task-Oriented Programming. YC AI Startup School Talk.
- Willison, S. (2025, May). Designing Agentic Loops. SimonWillison.net.
- Anthropic. (2025, September). Effective Context Engineering for AI Agents. Anthropic Engineering Blog.
- Steinberger, J. & Osmani, A. (2026, June). Loop Engineering: Architecting Autonomous Systems. O'Reilly Media / Essays.
- Terminal-Bench. (2025, March). Benchmark Analysis of Shell-Based Agents. GitHub / Research Paper.
- Model Context Protocol (MCP) Specification. (2024, November). Introduction to MCP 1.0. Anthropic / Open Source.
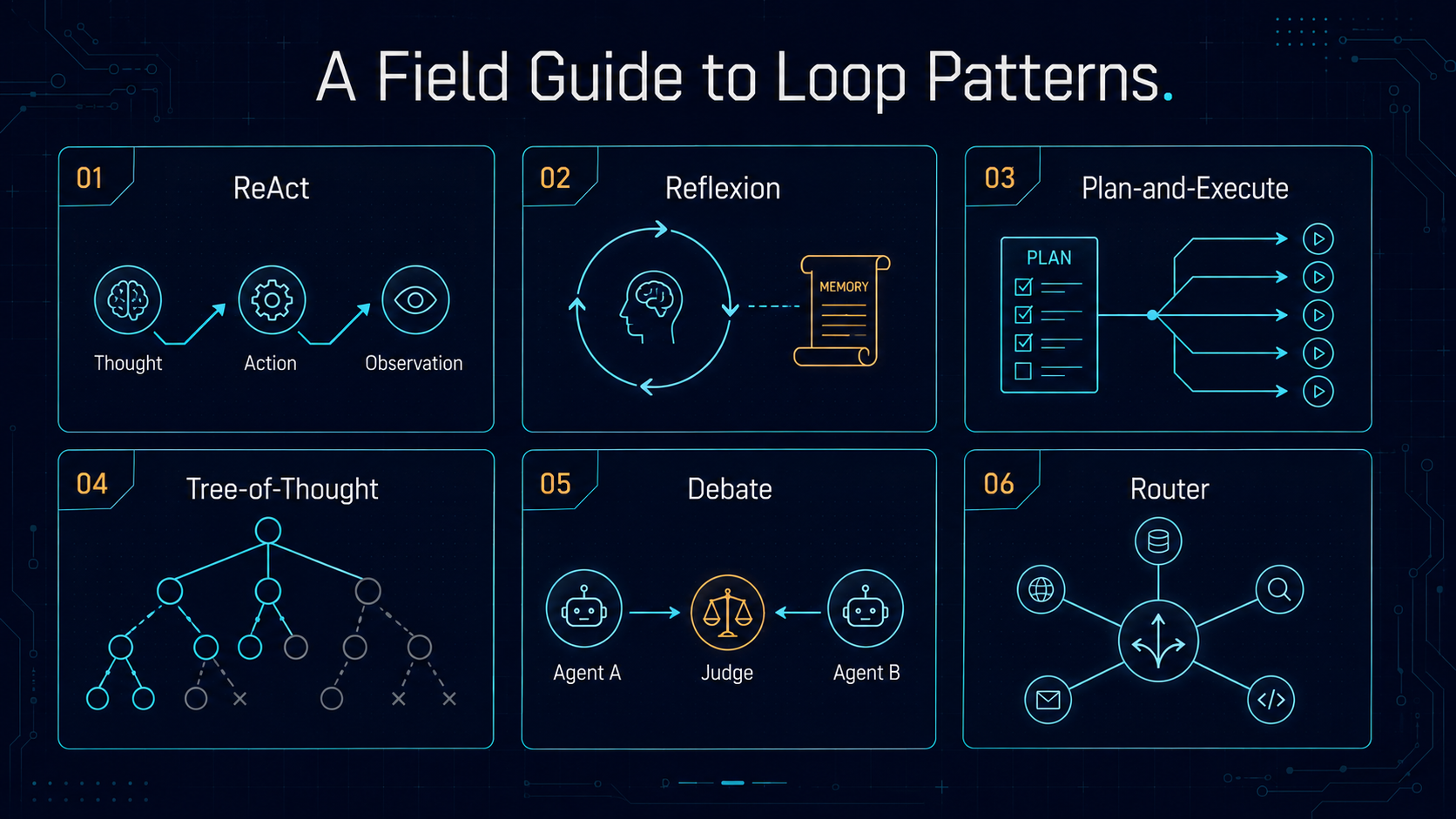
Chapter 3. A Field Guide to Loop Patterns
The transition from "chatbots" to "agents" is fundamentally a transition from linear inference to cyclical execution. In a chat interface, the model predicts the next token until a stop sequence is reached. In an agentic loop, the model’s performance is monitored, evaluated, and reintroduced as a fresh prompt. This architectural shift requires moving away from the "god-model" fallacy—the idea that a larger model will solve all problems—and toward "Loop Engineering" (Steinberger & Osmani, June 2026).
Effective loops are not accidental. They are deliberate patterns patterned after software design principles: modularity, error handling, and state management. This chapter examines the primary architectural patterns used to build self-correcting systems.