

TLDR;
- GPT4All is an open ecosystem created by Nomic AI to train and deploy powerful large language models locally on consumer CPUs.
- The goal is to create the best instruction-tuned assistant models that anyone can freely use, distribute and build on.
- GPT4All models are 3GB - 8GB files that can be downloaded and used with the GPT4All open-source software. Nomic AI maintains this software and helps users train customized models.
- High-quality training and instruction-tuning datasets are needed to create powerful assistant models. Nomic AI's Atlas platform helps curate and manipulate data.
- The latest open-source GPT4All dataset is available on HuggingFace, using the most recent version.
- The GPT4All community has an open datalake for contributing instruction and assistant tuning data for future models. Anyone can contribute.
- Data in the GPT4All datalake is open-sourced. You can contribute by opting-in with the Chat client.
- The datalake allows democratic participation in training large language models. Snapshots can be explored in Atlas.
GPT4All represents an exciting new frontier in generative artificial intelligence - one powered by community, collaboration, and decentralization. Developed by Nomic AI, GPT4All provides an open ecosystem enabling anyone to train and deploy customized large language models locally using consumer hardware.

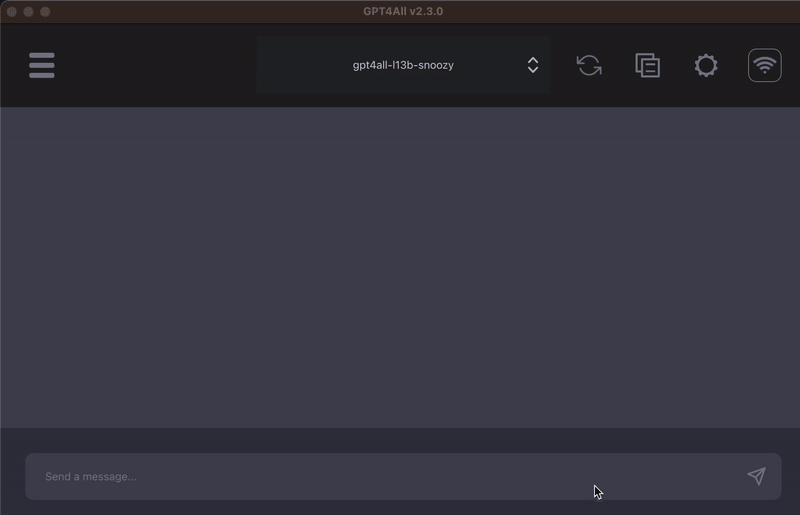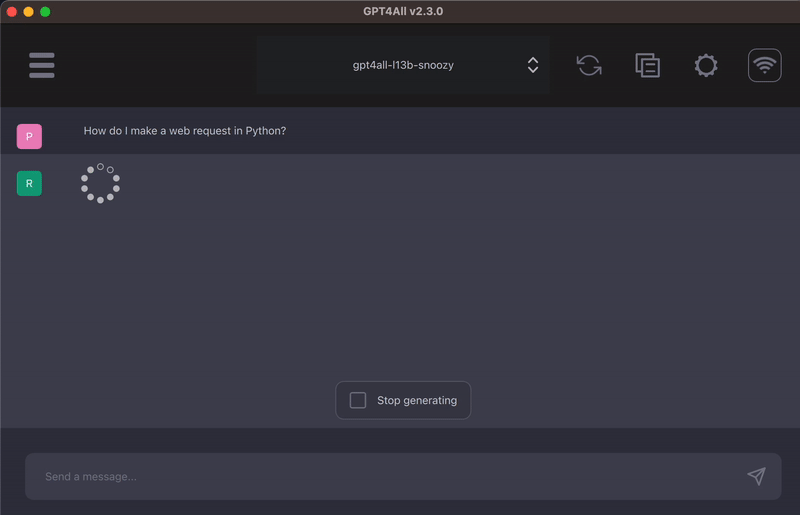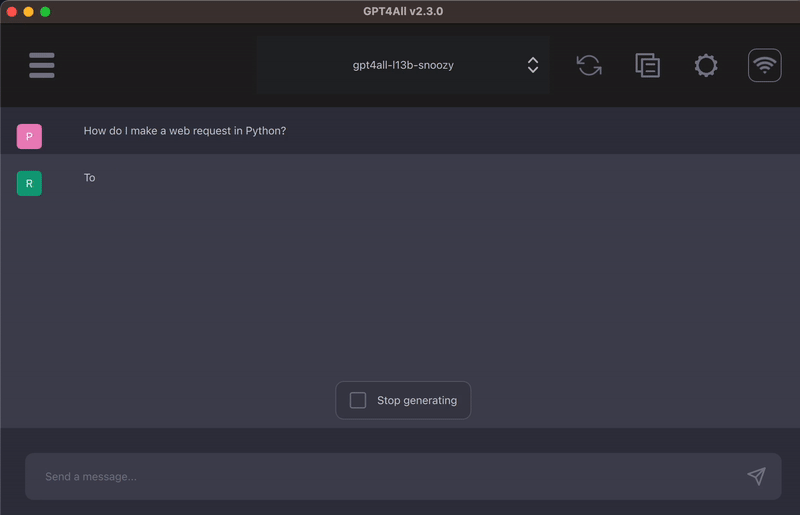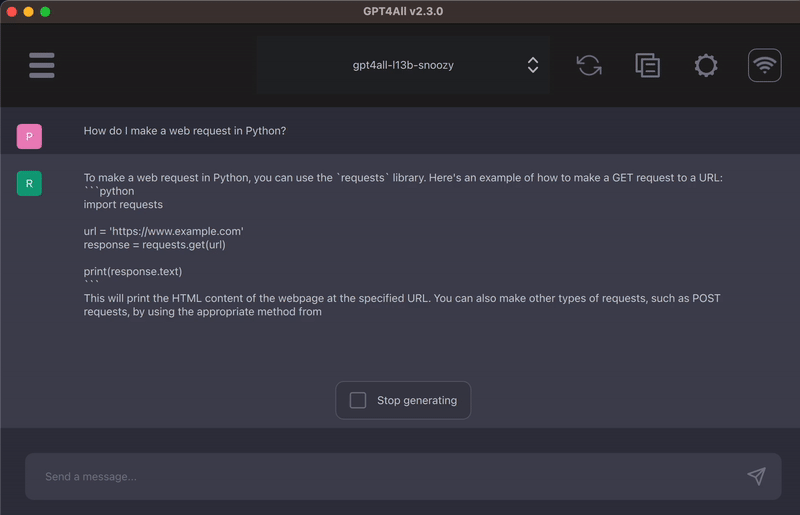
GPT4All: An Open Ecosystem for Local LLM Training
GPT4All represents a pioneering effort in decentralized and democratized AI research. Created by Nomic AI, GPT4All provides an open ecosystem that empowers anyone to train and deploy powerful large language models directly on their local consumer CPUs.
This local approach sets GPT4All apart from other LLM platforms that rely on cloud computing resources. By leveraging consumer hardware, GPT4All makes state-of-the-art natural language AI accessible to a much wider range of users, from individuals to small businesses. Democratizing access helps spur innovation and applications for LLMs beyond large tech companies.
A key advantage of the ecosystem model is its flexibility. The base GPT4All framework allows for extensive customization and tuning, enabling users to create LLMs specialized for their needs. The open-source nature also fosters collaboration, with the community contributing datasets, model optimizations, and more.
Nomic AI spearheads development and provides critical support, like the Atlas data platform and Hugging Face model distribution. But GPT4All remains community-driven at its core. This open, decentralized approach paves the way for the future of LLMs - one powered by creativity and participation from all.
Streamlined Installation for Popular Operating Systems
Getting started with GPT4All is incredibly simple thanks to the project's focus on accessibility and convenience. One-click installers make setting up the GPT4All ecosystem a breeze on Windows, MacOS, and Ubuntu Linux systems.
On Windows, users can download and execute the .exe installer available from the GPT4All website. The installer automatically configures the model and software in the background. Within minutes, users have a fully functioning local LLM ready to go.
MacOS users can similarly download and run the provided .dmg installer. The streamlined process installs all required components into the applications folder. Even users unfamiliar with the command line can be up and running quickly.
For Linux enthusiasts, a handy Snap installer enables effortless one-command installation on Ubuntu. This eliminates the need to manually install dependencies and other packages. The Snap wraps the entire GPT4All environment into a single self-contained unit.
Cross-platform support with optimized one-click installers exemplifies the project's commitment to democratizing access. In just minutes, anyone can start experiencing the power of a localized LLM regardless of their operating system.
Here are the installation options!

Training Cutting-Edge Assistant LLMs
The overarching goal of the GPT4All project is to develop the best instruction-tuned assistant models that are freely usable, distributable, and extensible by anyone. This objective focuses on both performance and accessibility.
On the performance side, GPT4All models utilize robust instruction tuning to optimize their ability to understand and follow natural language directives. This tuning, combined with ample high-quality training data, allows the models to handle a wide range of assistant-style tasks with high proficiency.
Equally important is GPT4All's commitment to open access. The models are intended to be used and built upon without licensing restrictions. This empowers developers and enthusiasts to freely explore applications using these advanced LLMs as a base. Democratized access also promotes broader innovation.
By pursuing both cutting-edge capabilities and extensive availability, GPT4All aims to drive the next generation of assistant LLMs. Powerful yet accessible models like these will help unlock the full potential of large language models across industries, businesses, and communities.
Convenient Model Distribution and Software
One of the hallmarks of the GPT4All ecosystem is the simplicity of accessing and deploying the latest models. Models are distributed as single 3GB to 8GB files that can be readily downloaded by users.
These model files are designed to plug into the GPT4All open-source software maintained by Nomic AI. The software provides an out-of-the-box interface to load models and start using them for text generation and other natural language tasks.
Nomic AI also assists users in training customized models tailored to their specific needs and data. The base GPT4All models can serve as excellent starting points for adaptation and fine-tuning. This support for customization is a key benefit enabled by the project's open-source ecosystem.
By handling the complexities of model training and deployment behind the scenes, GPT4All lets users focus on leveraging these powerful LLMs. Convenient access to state-of-the-art natural language processing, even on consumer hardware, helps unlock creativity and innovation.
Curating High-Quality Datasets
Behind every great AI model is great data. GPT4All relies on extensive datasets to train powerful instruction-tuned assistant models. These datasets require careful curation and preprocessing to achieve maximum quality.
Nomic AI's Atlas platform plays a crucial role in effectively manipulating and cleaning data for optimal model training. Atlas provides tools to filter, analyze, and transform diverse datasets into a form that yields top-notch performance from GPT4All models.
The availability of high-volume, high-quality training data is often a bottleneck when developing complex AI systems. By leveraging Atlas for rigorous dataset curation, the GPT4All project overcomes this hurdle. Users also benefit from Atlas when preparing their own custom datasets to fine-tune models for specific needs.
Careful data curation may occur behind the scenes, but it is foundational to delivering exceptional assistant LLMs that understand instructions and handle tasks with accuracy and reliability. The Atlas platform empowers the GPT4All ecosystem to efficiently generate and utilize massive high-quality datasets.
Accessing Cutting-Edge GPT4All Models
The most up-to-date, open-source GPT4All models are available through Hugging Face, a leading machine-learning community. Users should ensure they leverage the most recent model versions to benefit from the latest improvements.
Some of the latest GPT4All models currently available on Hugging Face include:
- wizardlm-13b-v1.1-superhot-8k.ggmlv3.q4
- ggml-model-gpt4all-falcon-q4_0
- nous-hermes-13b.ggmlv3.4_0
- GPTAIl-13B-snoozy.ggmlv3.94_0
- orca-mini-7b.ggmlv3.q4_0
- orca-mini-3b.ggmlv3.q4_0
- orca-mini-13b.ggmlv3.q4_0
- wizardLM-13B-Uncensored.ggmlv3.q4_0
- ggml-replit-code-v1-3b
- ggml-all-MiniLM-L6-v2-f16
- starcoderbase-3b-ggml
- starcoderbase-7b-ggml
- llama-2-7b-chat.ggmlv3.q4_0
With regular model updates, checking Hugging Face for the latest GPT4All releases is advised to access the most powerful versions.
Community-Powered Open Datalake
A key strength of the GPT4All ecosystem is its open datalake for crowdsourcing high-quality training data. This community-driven datalake allows anyone to contribute instruction and assistant tuning data to help enhance future GPT4All models.
By tapping into data contributions from the broader community, the datalake promotes the democratization and decentralization of model training. Instead of relying solely on closed datasets, GPT4All benefits from diverse open data gathering.
Participation is open to all - users can opt-in to share data from their own GPT4All chat sessions and other sources. This creates a virtuous cycle where model usage generates data to further improve the models. The open nature also enables new applications of instruction tuning and transfer learning.
Ultimately, the collective strengths of the GPT4All community act as a force multiplier for developing more capable LLMs. The open datalake exemplifies this collaborative, crowdsourced approach - where anyone can lend their support to create next-gen AI.
Open Data and Democratic Participation
Aligned with its commitment to accessibility, the GPT4All datalake makes all contributed data open source. This transparency enables broad community review and oversight.
Users can opt into sharing data from their Chat client sessions, providing a simple mechanism for open contribution. The system is designed to encourage wide participation - anyone can lend their data to help advance GPT4All model capabilities.
This democratic, crowdsourced approach to gathering training data is pioneering. By decentralizing and distributing data collection, GPT4All is able to leverage the collective wisdom of its community.
All data aggregated into the open datalake is visible and explorable within the Atlas platform. Atlas provides tools to analyze and visualize snapshots of the latest datalake contents. This open access and review keeps the process accountable.
Through open data and inclusive participation, the GPT4All datalake represents an innovative model for collaborative training data curation. It embodies the community-first ethos underpinning the entire GPT4All ecosystem.
Current Limitations of Smaller GPT4All Models
While the accessibility of GPT4All's localized approach is innovative, current models do face some limitations stemming from their smaller size. Most available GPT4All models have under 10 billion parameters.
Though sufficient for many basic natural language tasks, these smaller models lack the sheer sophistication and advanced capabilities unlocked by LLMs with dozens or hundreds of billions of parameters. Models like Anthropic's 70B LLama can exhibit impressively human-like reasoning and judgment.
Smaller models like those in the GPT4All ecosystem today may struggle with highly complex language understanding, reasoning, and generation tasks. Their output can be less coherent and grounded compared to exponentially larger models.
However, smaller localized models still bring significant value for basic NLP applications, providing a usable balance of performance and accessibility. As computational power grows, GPT4All will likely scale up model sizes considerably, closing this capability gap.
In the meantime, maximizing smaller models' potential through careful instruction tuning and encoding of knowledge into training data is an active area of research. But fundamentally, model size imposes constraints on achievable intelligence - a limitation GPT4All acknowledges while charting a path to democratization.
Summary
The GPT4All initiative, spearheaded by Nomic AI, heralds a new era of democratized and decentralized AI research and development. By offering an open ecosystem that places the power of large language models directly into the hands of individuals and small businesses, GPT4All shatters the convention that state-of-the-art AI requires massive computational resources or belongs exclusively to tech giants.
Resources

Comments