
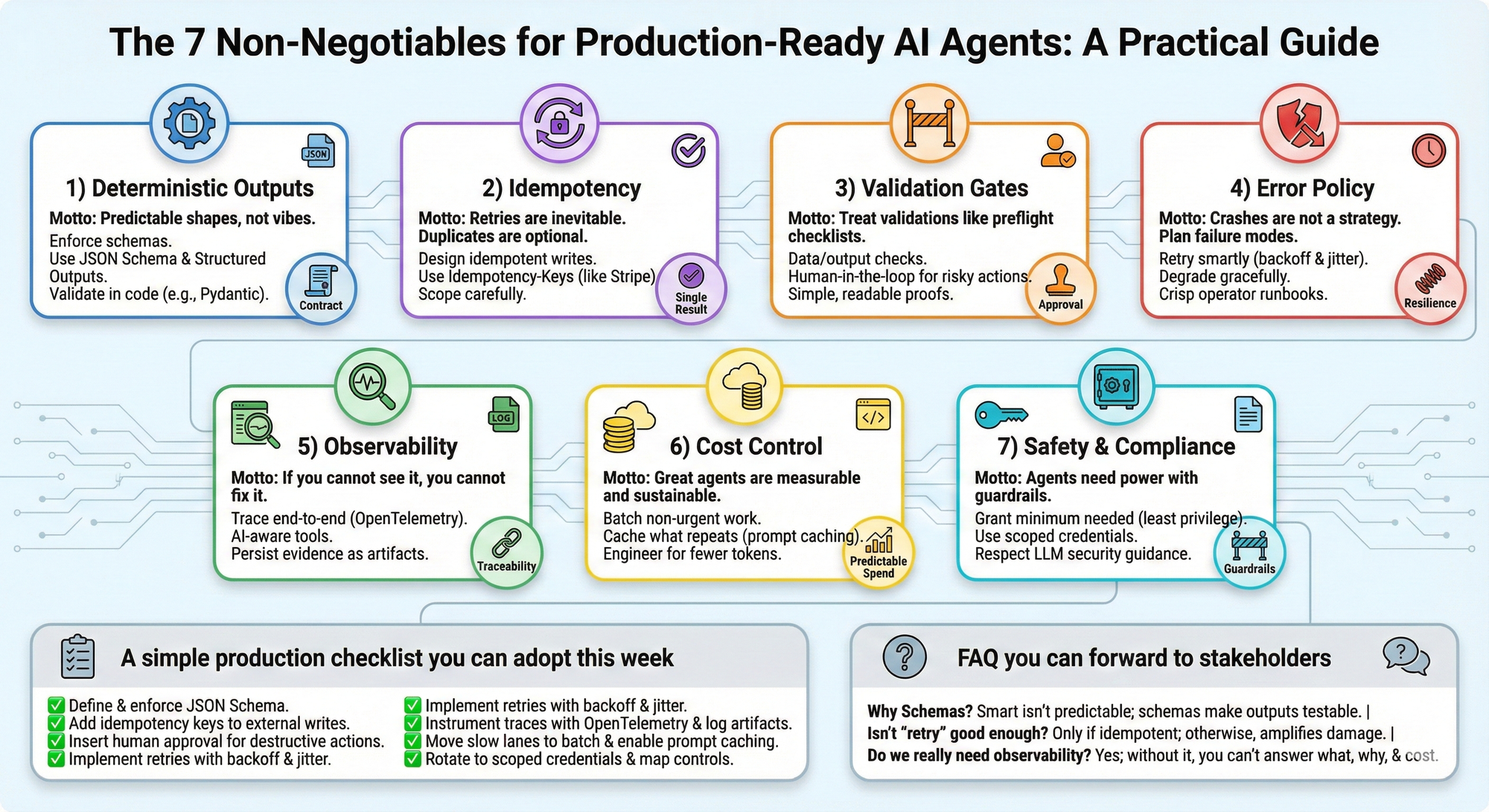
1) Deterministic outputs: schemas, stable files, explicit acceptance criteria
Customers and downstream systems need predictable shapes, not vibes.
- Enforce a schema at the boundary. JSON Schema is the industry standard for describing and validating structure. It defines both a Core and a Validation spec so machines and humans agree on what is acceptable. See the official JSON Schema specification for details, including the widely adopted 2020-12 draft that most tooling targets. This is the reference you can hand to auditors and integrators alike, not a blog post. Read the JSON Schema spec and its draft notes to understand supported keywords and portability.
- Use LLM features that guarantee adherence. Providers now offer hardened structured output modes that conform to a supplied JSON Schema. OpenAI’s Structured Outputs guarantee that model responses match your schema, which closes the gap that older JSON modes left open. That is an explicit reliability contract you can test. OpenAI’s guide on Structured Outputs explains how the API enforces your schema, and their announcement post clarifies why this goes beyond plain JSON validity. See the announcement context.
- Validate again in code. Even with model guarantees, treat outputs as untrusted. Python teams often use Pydantic to define models and run runtime validation, which can also auto-emit JSON Schema for downstream systems. Pydantic’s model docs and JSON Schema generation show how to keep the contract honest.
Practical acceptance criteria: “A run is only ‘done’ if the response passes JSON Schema validation, Pydantic model validation, and a set of business assertions.”
2) Idempotency: reruns never duplicate work or corrupt records
Retries are inevitable. Duplicates are optional.
- Design write operations to be idempotent. The gold-standard reference here is Stripe’s idempotency model. They explain how clients attach an
Idempotency-Keyso server retries return the original result instead of creating duplicate charges or emails. Their API reference and engineering blog are both worth studying because the concepts generalize to any stateful operation. Stripe API reference on idempotent requests and Stripe’s engineering write-up. - Scope idempotency carefully. Stripe’s newer API notes detail when two requests are considered the same operation and how long keys are honored, which helps you set retention windows and cleanup jobs. See the API v2 overview on idempotency keys.
Playbook: Persist a run-level idempotency key across your agent, tool layer, and messaging bus. Make every external write operation idempotent with that key.
3) Validation gates: preflight checks, post-step assertions, human summaries before external actions
Treat validations like preflight checklists.
- Data and output checks as first-class steps. Great Expectations formalizes “Expectations” and “Checkpoints” so your pipeline fails closed when data or outputs drift from policy. This is battle-tested in production data stacks and ports well to agent output validation. Great Expectations Checkpoints explain how to wire validations where they matter.
- Human in the loop for risky actions. Several industries now require human oversight before impactful actions. The EU AI Act explicitly calls for human oversight for high-risk systems, which is a strong compliance signal to add approval gates for destructive writes and customer-visible changes. See Article 14 on human oversight and the Official Journal publication reference so compliance teams can trace it. EU AI Act on EUR-Lex.
- Simple, readable proofs. Generate a human-readable summary of what the agent intends to do, with diffs or example records, and require a click-through approval. Zapier’s plain-language guide outlines approval flow patterns that pause automation until reviewed. Zapier on approval flows.
Gate set: preflight schema checks, PII checks, business rule assertions, and a short, human-readable “intent to act” summary that must be approved.
4) Error policy: retries with backoff, graceful degradation, clear operator prompts
Crashes are not a strategy. Plan failure modes.
- Retry smartly, not loudly. AWS guidance recommends exponential backoff with jitter to prevent thundering herds and improve resilience. This pattern has been used across Amazon SDKs for years and remains the default recommendation. AWS Architecture Blog on backoff and jitter and the Builders’ Library article expand on why to cap, randomize, and tune per operation. Timeouts, retries, and backoff with jitter.
- Degrade gracefully under stress. Keep core functions alive while trimming optional features. Cloud reliability guides from Google and AWS describe patterns that maintain partial service instead of failing hard. Google Cloud’s guidance on graceful degradation and AWS Well-Architected REL05 practice.
- Give operators crisp runbooks. When automated handling fails, humans need step-by-step prompts and rollbacks. Google’s SRE workbook and incident response playbooks are the canonical starting point. SRE workbook on incident response.
Minimum viable error policy: per-step retry budgets with jitter, circuit breakers for flaky tools, downgrade paths, and runbook links in every error notification.
5) Observability: logs, artifacts, and traceable decision notes
If you cannot see it, you cannot fix it.
- Trace your agents end to end. OpenTelemetry’s GenAI semantic conventions standardize span and attribute names for LLM calls, tools, and agent steps, which makes traces interoperable across vendors and teams. Instrument to these conventions so your data is portable. OpenTelemetry GenAI semantic conventions.
- Adopt AI-aware observability tools. Platforms such as LangSmith integrate with OpenTelemetry and provide specialized agent traces and evaluations, so you can debug tool use, prompts, and cost in one place. LangSmith’s OpenTelemetry tracing guide and their observability overview show concrete instrumentation paths. LangSmith Observability.
- Persist evidence as artifacts. Auditability requires durable files: prompts, outputs, CSVs, PDFs, and decision notes. MLflow and Weights & Biases both support logging and versioning artifacts and runs so you can reproduce how a decision was made. MLflow artifact APIs and W&B Artifacts overview.
Auditable run record: OpenTelemetry trace ID, per-step logs and prompts, saved artifacts, cost metrics, and the human approvals that unblocked external actions.
6) Cost control: predictable per-run spend using batching, caching, and code over tokens
Great agents are measurable and sustainable.
- Batch non-urgent work. OpenAI’s Batch API halves token prices for jobs that can tolerate delayed processing. That makes large evaluations, backfills, and nightly jobs affordable and predictable. OpenAI pricing page notes the discount and the Batch API guide explains how to submit jobs.
- Cache what repeats. Providers now discount reused prompt context. Anthropic’s prompt caching can reduce costs up to 90 percent for long, repeated contexts, while Google Vertex AI context caching documents explicit cache discounts for Gemini models. This is cost control with math, not magic. Anthropic’s prompt caching explainer and Vertex AI context caching overview.
- Engineer for fewer tokens. Caching and batching deliver predictable spend, and code that prunes prompts, limits output length, and reuses computed results does the rest. IBM’s neutral overview is a good primer to align product and engineering on caching terminology and tradeoffs. IBM on prompt caching basics.
Cost SLO: declare a target max cost per successful run, then enforce it with batching for slow lanes, caching for repeated context, and token budgets per step.
7) Safety and compliance: least privilege, scoped keys, documented boundaries
Agents need power with guardrails, not blanket access.
- Grant the minimum needed. The principle of least privilege is codified by NIST and widely used across compliance frameworks. Use it for human and machine identities, including agents and tools. NIST glossary definition and the NIST 800-53 AC-6 control for policy mapping. AC-6 overview.
- Use scoped credentials. Stripe’s restricted API keys illustrate “only the permissions required” for an integration, a pattern you should mirror across SaaS and internal services. Stripe key management and restricted keys and restricted key authentication.
- Respect LLM security guidance. The OWASP Top 10 for LLM Applications specifically calls out Excessive Agency, a risk that grows as agents gain tools. Mitigations include hard scoping, approvals, and audit trails. Point your security team to the official project so you are speaking the same language. OWASP LLM Top 10 project page and the updated 2025 PDF for policy specifics. OWASP 2025 PDF.
Boundary document: tools an agent may use, the data it may touch, the scope of each credential, and the human approvals required per risk tier.
A simple production checklist you can adopt this week
- Define a JSON Schema for your agent’s core outputs and enforce it with provider Structured Outputs plus Pydantic validation.
- References: OpenAI Structured Outputs, JSON Schema spec, Pydantic models.
- Add idempotency keys to every external write.
- References: Stripe idempotent requests.
- Insert a human approval step for destructive actions with a short, readable intent summary.
- References: EU AI Act human oversight, Zapier on approval flows.
- Implement retries with capped exponential backoff and jitter, then define graceful degradation paths.
- References: AWS on backoff and jitter, Google on graceful degradation.
- Instrument traces with OpenTelemetry GenAI conventions and log artifacts for audits.
- References: OpenTelemetry GenAI semconv, MLflow artifacts.
- Move slow lanes to batch and enable prompt context caching for repeat workloads.
- Rotate to scoped credentials and map controls to AC-6 and OWASP risks.
- References: NIST AC-6 least privilege, OWASP LLM Top 10, Stripe restricted keys.
FAQ you can forward to stakeholders
- Why are we spending time on schemas if the model is smart? Because smart is not predictable. Schemas make outputs testable and contractable. Providers like OpenAI now enforce schema matching so you can automate acceptance. Structured Outputs guide.
- Isn’t “retry” good enough? Only if idempotent. Otherwise you will amplify the damage. AWS shows why backoff with jitter is the safest retry baseline. AWS Builders’ Library.
- Do we really need observability for agents? Yes. Without traces and artifacts, you cannot answer what the agent did, why, and at what cost. OpenTelemetry’s GenAI conventions and AI-specific tools like LangSmith exist for exactly this. OpenTelemetry GenAI, LangSmith tracing.
Over to you: Which of the seven non-negotiables is your current bottleneck, and what is the smallest experiment you could run this week to unblock it?

Comments