
Demystifying the Mind of Large Language Models
The release of systems like ChatGPT in 2022 sparked sensational headlines about the dawn of artificial general intelligence (AGI) and fears that AI may soon become sentient or reach "God mode." Terms like "technological singularity" proliferate in both media coverage and developers' descriptions of large language models (LLMs).
However, this anthropomorphizing of LLMs fuels misconceptions. In this series, I will demystify the inner workings of systems like GPT-3/4/ChatGPT to expose their current limitations compared to human cognition.
Like Smeagol from Lord of the Rings, some AI researchers cherish their creations beyond rationality. And media outlets capitalize on AI anxiety for attention.
But probing beneath the hype reveals LLMs are not the omnipotent AGI some proclaim them to be. I will attempt to unpack how LLMs actually work under the hood (in as much a non-technical way as possible) - relying on statistical patterns in massive text corpora rather than human-like understanding. Analyzing their underlying methodology shows current LLMs lack capabilities we take for granted, like memory, intentionality, and reasoning.
While remarkable as text generators, treating LLMs as deeper thinking machines risks severe disappointment. LLMs cannot always converse fluently, answer broad questions intelligently, or process instructions flexibly as humans can. At least their latest incarnations cannot without serious prodding.
Their abilities are narrow and brittle rather than general. Demystifying the "minds" of LLMs helps calibrate expectations and focus progress on methods beyond simply scaling up current techniques. For now, LLMs are productive but limited tools, not the awakening of artificial consciousness.
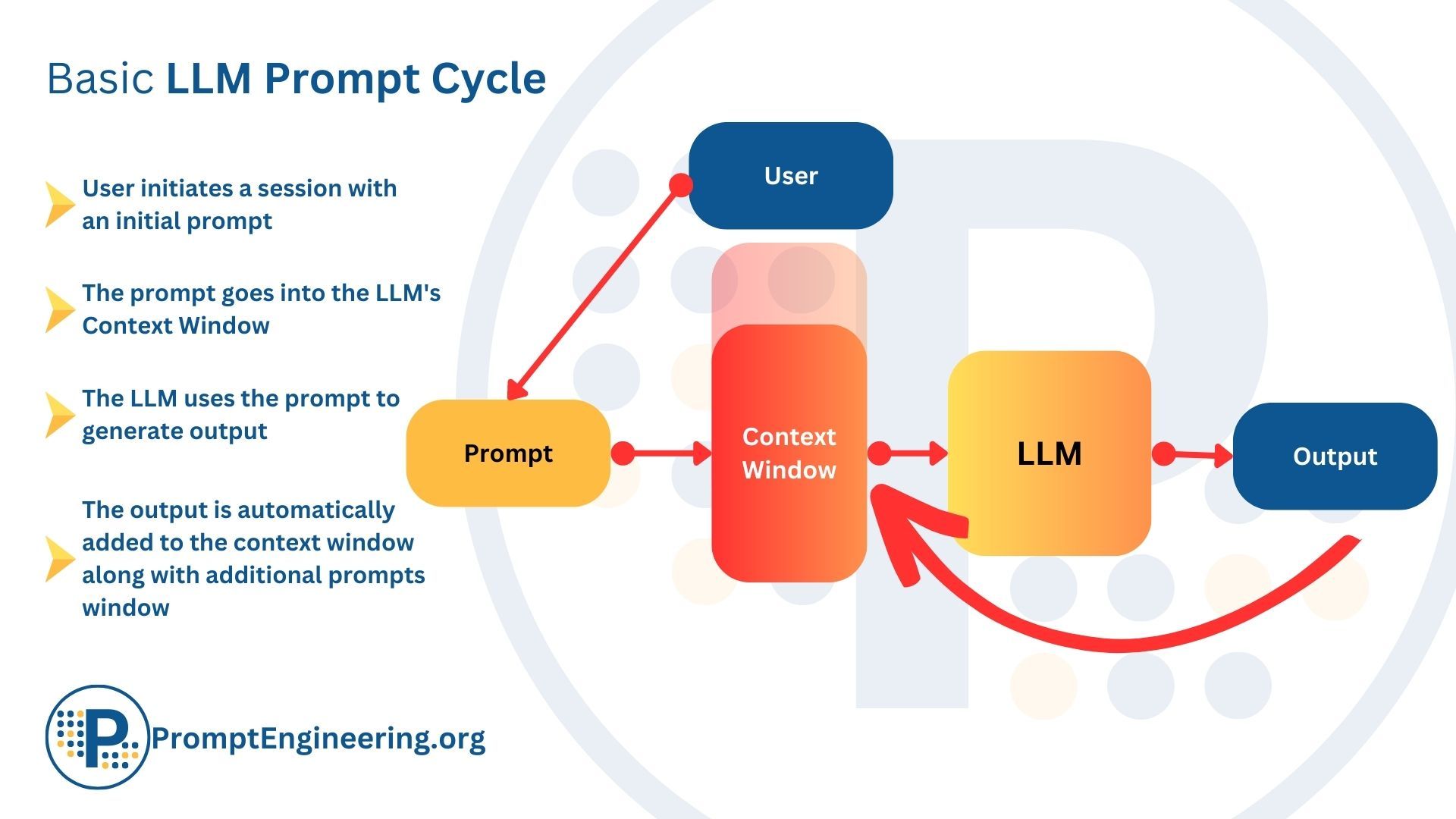
LLMs, such as GPT models, lack a conventional memory mechanism. Instead, they rely on a context window for processing input, making them fundamentally autoregressive in nature.
LLMs Have No Memory Outside of the Context Window
Large language models (LLMs) like GPT do not have any long-term memory that persists outside of the context window provided in the prompt. Unlike humans who can store information in memory and refer back to it later, LLMs can only "remember" what is contained within the limited context they are given. This is because LLMs are autoregressive - they predict the next token statistically based solely on the preceding context. They have no separate memory store to draw on.
The Context Window as the Memory of LLMs
- Defining Context Window: The context window is a segment of recent input data that LLMs utilize to generate responses. It can be imagined as the 'short-term memory' of the model. Unlike human memory which can recall events or information from the past without constant reminders, LLMs rely entirely on this context window for any prior information.
- How it Functions: When a user interacts with an LLM, such as posing a question or giving a command, the model doesn’t “remember” past interactions. Instead, it processes and responds to the immediate context provided. Thus, if an important detail or command is left out, the LLM has no way of accessing it unless it's within its current context window.
LLMs Must "Read" Information to "Think" About It
Because LLMs lack a working memory, they can only "think" about information that is directly included in their prompt or limited context window input. Humans can read material, comprehend it into our memory, and then think about it later even if the original text is no longer present. We retain and process information in our memory flexibly over time.
In contrast, LLMs have no capability to comprehend and retain information in memory for later processing. Their statistical text generation is fully dependent on the context window supplied to them. An LLM cannot "think" about a concept or refer back to an idea unless it is explicitly included in the prompt or context.
Essentially, an LLM must "read" any information requiring processing within its input text each time. It has no memory to look back on what it may have read previously. This tight coupling between the LLM's input text and output text generation contrasts greatly with human cognition, which can learn information once and flexibly apply it many times from memory. Understanding this limitation is key to prompting LLMs effectively rather than assuming human-like recall.
LLMs: Reading without Transient Memory
- Lack of Transient Memory: Unlike human cognition, which can read and temporarily store information in a transient memory for processing, LLMs don't have this capability. They only "think" or process based on the immediate input they receive.
- Implications: This means that LLMs cannot sequentially process multi-step instructions or extended narratives without the full context being available to them. In tasks where understanding the entire narrative or sequential instructions is crucial, this limitation becomes particularly evident.
LLMs Cannot Read Without Thinking
Vice versa, LLMs cannot truly comprehend and retain information from reading without incorporating it into their predictions. Humans can read material without immediately connecting it to output or predictions.
But LLMs do not have this transient "reading memory" since their only purpose is to generate probable next tokens. The context window serves as their sole "memory" source. Any information not contained there cannot be retained or referred back to by the LLM.
The Context Window Acts as an LLM's Only "Memory"
Because LLMs are statistical models without human-like memory, the context window provides their only form of memory. This window of previous text likelihoods is what the LLM uses to generate the next most probable token.
So while a human can read, comprehend, store in memory, and later reference information, the LLM cannot look beyond the scope of the context window to inform its next output. This core limitation stems from how LLMs work - they leverage no additional memory system.
The Statistical Nature of LLMs
- Word Prediction Mechanism: At its core, an LLM is trained to predict the next word or sequence of words based on patterns it has learned from vast amounts of data. It doesn’t truly “understand” the content but instead uses statistics to guess the most probable next word or phrase.
- Constraints of Autoregressiveness: The term 'autoregressive' describes the nature of these models where they generate responses based on their own previous outputs. This approach makes them dependent on the initial prompt or the evolving context window for generating coherent and contextually relevant outputs.
Why LLMs are Called Autoregressive
- Defining Autoregressiveness: An autoregressive model, in the context of LLMs, refers to the method of generating outputs based on its own prior outputs. It's like a chain reaction, where each link or word depends on the preceding one.
- Practical Implications: The autoregressive nature of LLMs has both strengths and limitations. While it enables the generation of fluent and coherent text, it also makes the model sensitive to the context window. If the prompt or command is ambiguous, incomplete, or not included in the context window, the LLM might produce outputs that are off-mark or not as expected by the user.
Distinguishing Memory from Knowledge in LLMs
When discussing the capabilities of LLMs, it is important to distinguish between memory and knowledge. Knowledge refers to information that is contained within the model's parameters - either from its original training data or facts provided in a prompt. This constitutes the LLM's stored knowledge about language and the world, encoded in its machine learning model.
However, as discussed earlier, LLMs lack any transient, working memory where they can store information temporarily for ongoing cognition. Humans actively use working memory to comprehend and make connections between concepts. We store pieces of information in memory while reading or thinking, before we are ready to produce output.
But LLMs have no such transient memory store. They cannot dynamically memorize information as part of thinking - the context window constitutes their sole memory source directly tied to text generation. LLMs contain vast amounts of knowledge but cannot hold pieces of information in a flexible, short-term memory to inform their processing. This lack of working memory is a core limitation compared to human cognition.
So in summary, LLMs possess knowledge but crucially lack memory. Their knowledge is contained in their parameters, while their memory is limited to the context window used for statistical generation. This key distinction helps illuminate differences between LLMs and human-like general intelligence.
LLMs Cannot Predict Output Length
An additional limitation of LLMs is that they cannot predict or control the length of their generated text output in terms of word count. Humans consciously think about how long they want their written or spoken output to be before they start. But LLMs have no inherent sense of intended output length. This is because they generate text statistically one token at a time based solely on the preceding context window.
LLMs cannot dynamically determine when they have reached a certain word count or how many more words their output will contain. The only length limitation is the maximum token count set by the user. The LLM has no internal mechanism to target a specific word count or adaptively determine output length. It simply generates the most likely next token iteratively until reaching the set maximum number of tokens. So while humans can deliberately craft output of a desired length, LLMs lack this basic capability. Their output length emerges stochastically rather than by design.
LLM's Approach to Itemized Responses:
When tasked with generating a list or a specific number of points on a topic, LLMs, to maintain accuracy and clarity, will often label each point sequentially. This structure helps in ensuring that the generated output adheres to the required format and that the user can easily distinguish between separate points.
Benefits of Labeling Each Point:
- Clarity and Distinction: By labelling each point, the LLM provides a clear distinction between individual items or ideas. This separation ensures that the user can easily understand and differentiate between the various points being made.
- Adherence to User Requests: When users specify a particular number of points or items, labelling aids in meeting this specification. It becomes easier for both the user and the LLM to track if the output is aligning with the given instruction.
- Enhanced Readability: Sequentially labelled points provide a structured format, enhancing the readability of the output. It allows users to follow the content in an organized manner, especially when dealing with complex topics or extensive lists.
LLMs Cannot Reliably Follow Ordered Instructions
Additionally, LLMs do not have the capability to reliably follow ordered instructions for output generation. For example, if prompted to generate a certain number of points on a topic, the LLM cannot ensure it covers the exact specified number of points without repetitive labeling. Humans can consciously count and track how many items they have listed so far. But the LLM has no sense of its output or ability to actively verify if it has covered the requested number of points.
The LLM generates probabilistically based on the context window rather than verifying its compliance to instructions. It has no innate concept of counting what it has produced so far. The only way to reliably get an LLM to follow ordered generation instructions is through repetitive labeling - manually indicating in the output text "Point 1", "Point 2", etc. But this is an inelegant workaround rather than true comprehension and tracking of assigned output goals. LLMs lack the capability to independently follow prescribed ordered generation tasks.
The Nature of LLM Outputs:
LLMs, when generating text, do not have an inherent mechanism to determine the exact number of words they will produce for a particular prompt. Instead, their primary function is to predict the next word or sequence of words based on the current context window and the patterns they've learned during their training.
Token Limit as a Constraint:
- Defining Tokens: Tokens in the context of LLMs refer to chunks of text, which can be as short as one character or as long as one word. LLMs have a maximum token limit for each generation, which is a set number of tokens they can produce in a single output.
- The implication of Token Limit: While LLMs cannot predict the exact word count of their output, they are constrained by this token limit. When asked to generate a piece of text, they will continue predicting the next token until they either complete the thought (as determined by their training) or reach the set token limit.
Why Exact Word Prediction is Challenging:
The core functionality of LLMs revolves around predicting the most likely next token based on context and not the length of an output. Predicting the exact number of words for a given input would require a different model architecture or an additional layer of processing on top of the current LLMs. Furthermore, the fluid and dynamic nature of language makes it challenging to set a fixed word count for various prompts, as responses can be elaborated or condensed based on context and training data.
Prompting LLMs Requires Understanding Their Limits
When crafting prompts for LLMs, it is important to understand their limitations and avoid anthropomorphizing their capabilities. For instance, many users prompt LLMs to generate text of a certain length or ask the LLM to "imagine" or "think" about certain concepts. However, as established earlier, LLMs have no innate sense of intended output length or ability to deliberately imagine or comprehend ideas.
LLMs cannot think or imagine in the human sense - they simply generate statistical continuations without any deliberate comprehension or intent. Prompting an LLM to "imagine a story" or "describe what you dreamed about last night" imbues it with the human-like consciousness it does not possess. LLMs have no sense of imagination, dreams, desires, or contemplation. They generate text probabilistically not imaginatively.
Understanding the boundaries between LLMs' statistical text generation versus true human cognition is key for effective prompting. Rather than anthropomorphizing, prompts should focus on providing relevant seed text and allowing the LLM to leverage its statistical capabilities. Prompting the LLM as if it can think or has goals often yields poor or nonsensical results. Keeping the LLM's actual limits in mind allows for prompting its strengths rather than arbitrarily imposed human attributes.
The Illusion of Cognition:
- "Imagining" and "Thinking" or similar: When users ask an LLM to "imagine" or "think", they might expect a response rooted in some form of deep cognitive processing or creative exploration. However, LLMs don't "think" or "imagine" in the human sense. Instead, they generate responses based on patterns in data they've been trained on.
- Deciphering Prompts: For LLMs, a directive to "imagine" doesn't invoke an imaginative process but rather signals the model to generate a hypothetical or creative response based on the context provided.
Length Specific Requests:
- Ambiguity in Length Directives: When users ask for a response of a "certain length," it poses a challenge for LLMs. While they can adhere to token limits, predicting the exact number of words or paragraphs can be ambiguous without precise instructions.
- Effectiveness of Clear Constraints: For more effective responses, users should provide clearer constraints. For instance, instead of vaguely asking for a "short explanation," specifying "a two-sentence explanation" might yield more desired results.
Read the next article in this series:
 Sunil Ramlochan - Enterpise AI Strategist
Sunil Ramlochan - Enterpise AI Strategist
Takeaway
While large language models like the GPT family exhibit impressive fluency, their underlying mechanisms differ fundamentally from human cognition. Unlike the rich episodic and semantic memory of the human mind, LLMs rely solely on the limited context window provided to them.
They cannot genuinely comprehend or retain information, imagine hypotheticals, or plan output length. Their strength lies in statistical prediction rather than conceptual understanding. Recognizing these limitations is key to understanding how LLMs work and prompting them effectively.
Rather than anthropomorphizing, we must appreciate LLMs for what they are - powerful statistical engines for generating fluent text, not sentient beings with human-like consciousness. Keeping their boundaries and capabilities in perspective will allow us to utilize these transformative models appropriately and open up new frontiers in AI creativity.
However, we must also continue innovating to reduce their reliance on surface patterns and increase unsupervised comprehension. Only by clearly understanding the current limits of LLMs can we progress responsibly towards more capable and trustworthy language AI.
In subsequent lessons we will discuss how we can attempt to overcome these memory limitations.