

Artificial intelligence (AI) technology is rapidly advancing, and one of the latest breakthroughs is the use of latent diffusion models to generate complex and realistic audio and images.
Recently text-to-audio (TTA) systems have been a topic of interest due to their ability to generate audio based on text descriptions. However, while text-to-speech AI's have made improvements to the point we cannot discern which is real and which is AI, previous TTA systems had limited generation quality and computational efficiency.
A new study has proposed a solution called AudioLDM, which improves the quality and efficiency of TTA generation. This technology is still in its infancy, but it has the potential to revolutionize the way we create and consume audio content. In this article, we will discuss AudioLDM's approach, features, advantages, and potential applications.
But First..Audio Samples
The audio samples generated by latent diffusion models are impressive. They demonstrate the technology's ability to generate sound based on various inputs, such as images or prompts. The models can also modify existing audio, such as upscaling low-quality audio or transforming the sound of a trumpet to resemble a child singing.
The technology can generate a wide range of sounds, from space shuttles fighting in space to a man speaking in a small room. The models can differentiate between sounds of different environments, such as the echo in a large room versus a studio. Additionally, the technology can also simulate the sound of water hitting a hollow metal surface or a stream of water hitting a fireplace. The audio can simulate an environment, such as the sound of waves crashing on a beach or the intergalactic sounds of outer space.
While some of these audio samples are peaceful and calming, others are eerie and creepy.
You can listen to all the samples at the official githib release here:

So What is Audio Latent Diffusion Model (AudioLDM)?
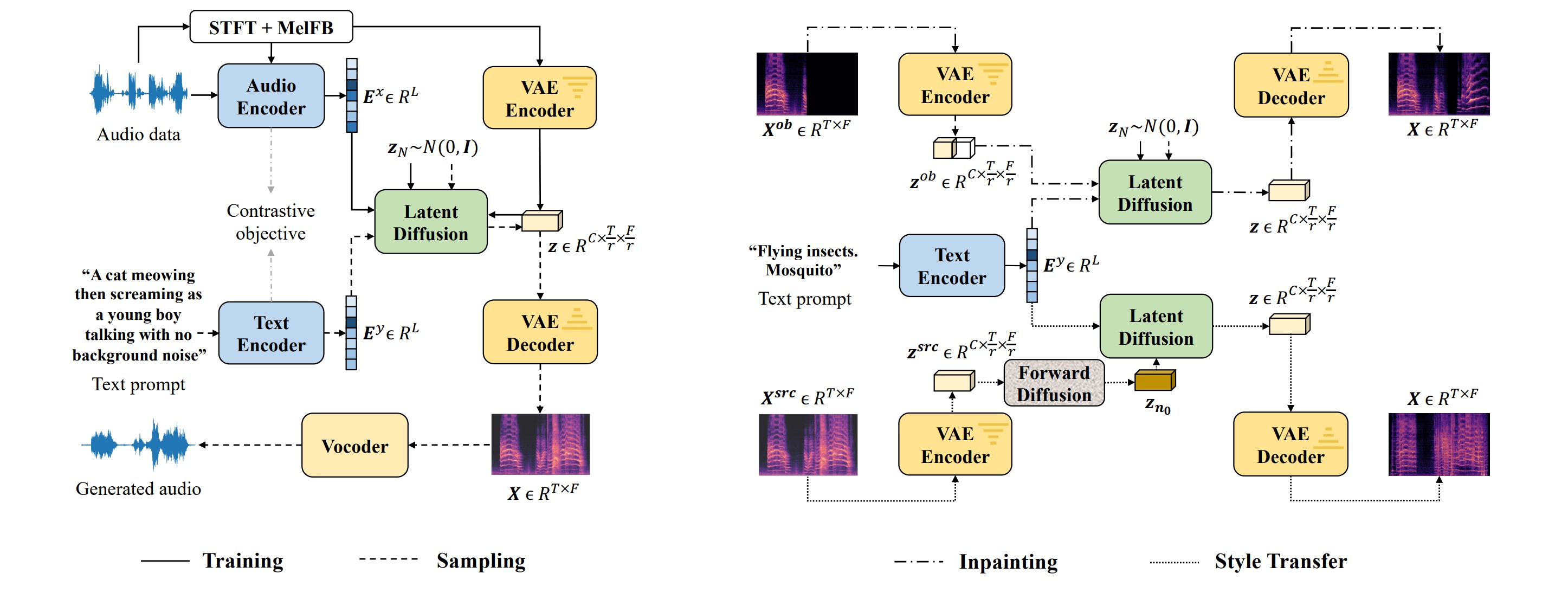
AudioLDM is a TTA (text-to-audio) system built on a latent space that learns continuous audio representations from contrastive language-audio pretraining (CLAP) latents. The system uses pretrained CLAP models to train latent diffusion models (LDMs) with audio embedding and text embedding as a condition during sampling.
By learning the latent representations of audio signals and their compositions without modeling the cross-modal relationship, AudioLDM is advantageous in both generation quality and computational efficiency.
Basically this is a type of AI technology that generates audio or images based on a prompt or an input image. It is similar to stable diffusion, which is used to generate images, but AudioLDM is specifically designed for audio generation.
Try Text-To-Audio on HuggingFace Here

Under the Hood of Audio LDM
I won’t go into much detail here, simply put latent diffusion models are complex algorithms that require a deep understanding of audio processing. The research behind audio LDM is extensive, and it involves several models that generate different types of audio.
The technology can generate a wide variety of sounds, ranging from space shuttles fighting in space to a man speaking in a small room. The models can differentiate between sounds of different environments, such as the echo in a large room versus a studio.
AudioLDM's Features
AudioLDM can generate various types of audio, including text-conditional sound effects, human speech, and music. It is trained on a single GPU without text supervision, which makes it computationally efficient. Additionally, AudioLDM enables zero-shot text-guided audio manipulations, such as style transfer, inpainting, and super-resolution.
Inpainting and Super Resolution
One of the most interesting applications of latent diffusion models is inpainting, where the AI fills in missing audio or image data. The technology can analyze the existing data and predict what the missing portion should sound or look like. This technology has the potential to revolutionize the way we edit and repair audio and image files. Similarly, the technology can also upscale low-quality audio or transform the sound of a trumpet to resemble a child singing.
Image to Music Conversion
AudioLDM also allows for the conversion of an image into an audio file. This is achieved using the same technology as the text to audio generation. I had issues getting it to work, maybe you may have better luck.

AudioLDM's Advantages
The researchers trained AudioLDM on AudioCaps with a single GPU, and it achieved state-of-the-art TTA performance measured by both objective and subjective metrics, such as the frechet distance. AudioLDM's approach provides better generation quality and is computationally efficient compared to previous TTA systems. Moreover, AudioLDM is the first TTA system that enables zero-shot text-guided audio manipulations.
The Power of AudioLDM: Exploring its Potential Applications
AudioLDM revolutionary technology in the field of audio generation that has numerous potential applications. There are centainly thousands of use cases but let’s just examine a few:
Revolutionizing the Music Industry: Music is an integral part of our lives and the way it is created and experienced is constantly evolving. AudioLDM has the potential to revolutionize the music industry by enabling artists to generate music from text and visual inputs. This new approach to music creation opens up a world of possibilities and can lead to the creation of unique and innovative compositions. Think about what AI Art is doing now to the graphic, art and film industries.
Enhancing the Film Industry: The film industry is always looking for new and innovative ways to engage viewers and provide them with a more immersive experience. AudioLDM can be used to generate immersive audio environments, adding depth and excitement to the viewing experience. This technology can also be used to create a more engaging soundscape for video games, further enhancing the player's experience.
Empowering People with Hearing Disabilities: In the medical industry, AudioLDM has the potential to make a significant impact on people with hearing disabilities. The technology's ability to enable text-guided audio manipulations can provide new opportunities for individuals with hearing impairments to experience the world of sound in new and exciting ways.
Enhancing Educational Content: Another potential application of AudioLDM is in the field of education. The technology can be used to generate audio explanations for various subjects, making them more accessible and engaging for students. This can be especially helpful for visual learners who may struggle with traditional text-based materials. Additionally, AudioLDM can be used to generate audio content for individuals with learning disabilities, making education more inclusive and accessible.
Transforming the Broadcasting Industry: AudioLDM also has the potential to transform the broadcasting industry. The technology can be used to generate high-quality audio content for radio and podcasts, allowing for the creation of more immersive and engaging broadcasts. Additionally, AudioLDM can be used to enhance the audio quality of live broadcasts, making them sound more professional and polished.
Gaming Industry: The gaming industry is constantly looking for new and innovative ways to enhance the player's experience. One area where technology can make a significant impact is in audio. AudioLDM is a technology with the potential to revolutionize the way audio is generated and used in the gaming industry.
Takeaway
AudioLDM is a promising new technology that has the potential to revolutionize the way we generate and consume audio content. The models are complex and require a deep understanding of audio processing, but they can generate a wide variety of sounds based on different inputs. Audio LDM has the potential to be used in various applications, such as generating immersive audio environments or repairing damaged audio files. As this technology continues to evolve, we can expect to see even more exciting applications in the future.
Resources
 haoheliu
haoheliu
Comments